流处理系统中状态的表示和存储
流处理系统处理的数据往往是没有边界的:数据会一直从数据源输入,用户需要看到 SQL 查询的实时结果。与此同时,流处理系统中的计算节点可能出错、失败,可能根据用户的需求实时扩容、缩容。在这一过程中,系统需要能够高效地将计算的中间状态在节点之间转移,并持久化到外部系统上,从而保证计算的不间断进行。
本文介绍了工业界学术界中流处理系统状态存储的三种方案:存储完整状态 (Flink 等系统),存储共享状态 (以 Materialize / Differential Dataflow 为例),存储部分状态 (以 Noria (OSDI ‘18) 为例)。这些存储方案各有优势,可以为未来的流处理引擎开发提供一些借鉴意义。
引入
假设某个购物系统中有两个表:
visit(product, user, length)表示用户查看某产品多少秒。info(product, category)表示某个产品属于某个分类。
现在我们要查询:某个分类下用户查看产品最长的时间是多少。
CREATE VIEW result AS
SELECT category,
MAX(length) as max_length FROM
info INNER JOIN visit ON product
GROUP BY category这个查询中包含两表 Join 和一个聚合操作。后文的讨论都将基于这个查询进行。
假设系统现在的状态是:
info(product, category)
Apple, Fruit
Banana, Fruit
Carrot, Vegetable
Potato, Vegetable
visit(product, user, length)
Apple, Alice, 10
Apple, Bob, 20
Carrot, Bob, 50
Banana, Alice, 40
Potato, Eve, 60此时,查询的结果应该是
category, max_length
Fruit, 40
Vegetable, 60代表 Fruit 分类被用户查看最长的时间为 40 秒(对应 Alice 访问 Banana 的时间);Vegetable 分类被用户查看的最长时间为 60 秒(对应 Eve 访问 Potato 的时间)。
在常见的数据库产品中,系统通常来说会为这个查询生成如下的执行计划(不考虑 optimizer):
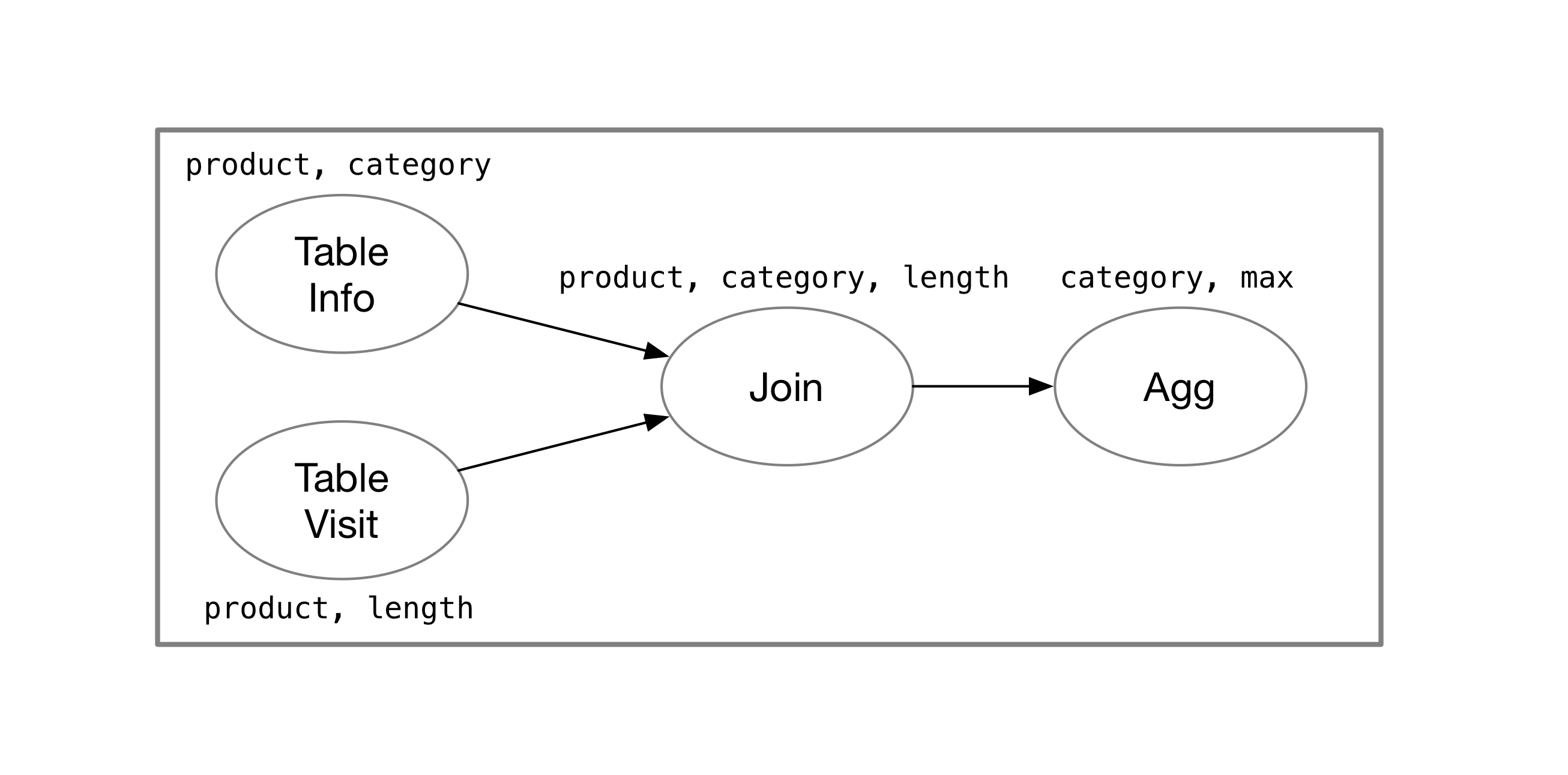
流处理系统的执行计划和常见数据库系统的计划没有太多区别。下面将具体介绍各种流处理系统会如何表示和存储计算的中间状态。
Full State - 算子维护自己的完整状态
诸如 Flink 的流处理系统持久化每个算子的完整状态;与此同时,流计算图上,算子之间传递数据的更新信息。这种存储状态的方法非常符合直觉。前文所述的 SQL,在 Flink 等系统中大致会创建出这个计算图:
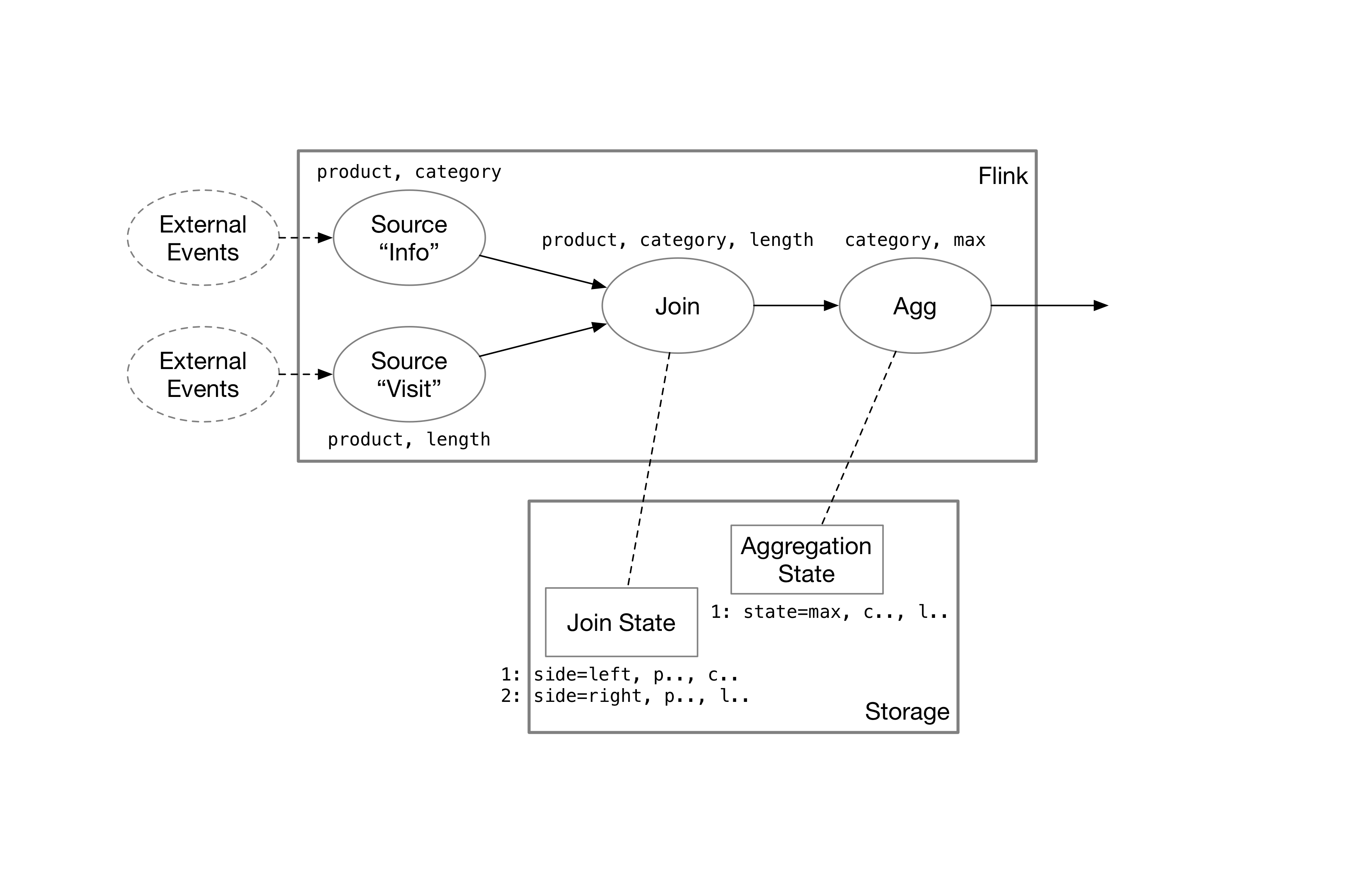
数据源会发出增加一行或是减少一行的消息。经过流算子的处理,这些消息会转变为用户需要的结果。
Join State 的存储
数据源的消息进入系统后,碰到的第一个算子就是 Join。回顾 SQL 查询的 Join 条件: info INNER JOIN visit ON product。Join 算子在收到左侧 info 的消息后,会先将 visit 一侧的 product 相同的行查出来,然后发给下游。之后,将 info 一侧的消息记录在自己的状态中。对于右侧消息的处理也如出一辙。
比如,现在 visit 一侧收到 Eve 对着 Potato 看了 60 秒 + Potato Eve 60 的消息。假设此时 info 一侧的状态已经有了四条记录。
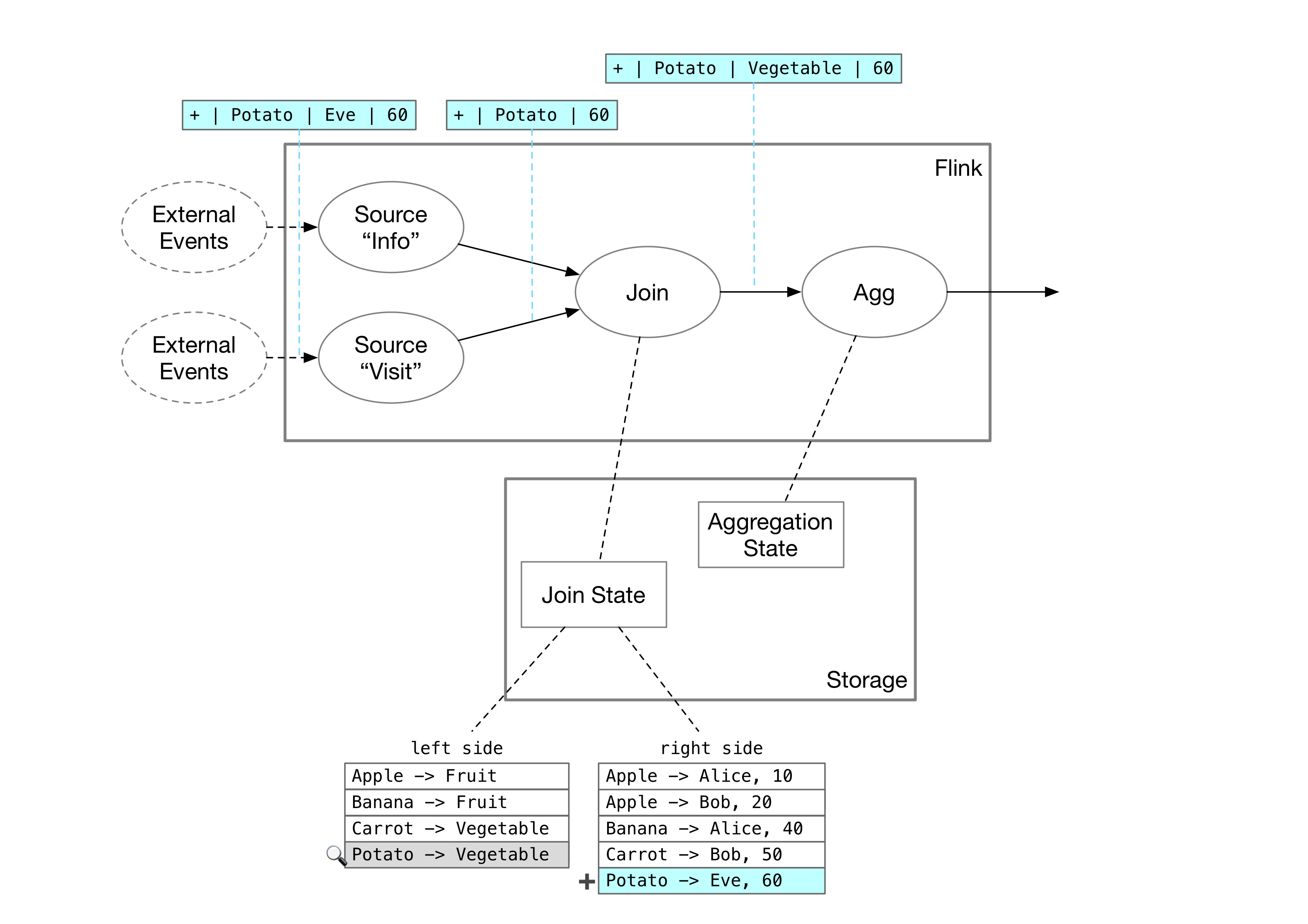
Join 算子会查询 info 一侧 product = Potato 的记录,得到 Potato 是 Vegetable 的结果,之后将 Potato, Vegetable, 60 发给下游。
而后,visit 一侧的状态会加入 Potato -> Eve, 60 的记录,这样一来,如果 info 发生变化,Join 算子也能对应 visit 给下游发送 Join 算子的更新。
Aggregation State 的存储
消息接下来被传递到了 Agg 算子上,Agg 算子需要根据 category 分组,计算每个 category 中 length 的最大值。
一些简单的 Agg 状态 (比如 sum) 只需要记录每一个 group 当前的值就行了。上游发来 insert,就将 sum 加上对应的值;上游发来 delete,就将 sum 减去对应的值。所以,诸如 sum、不带 distinct 的 count 等聚合表达式需要记录的状态非常小。
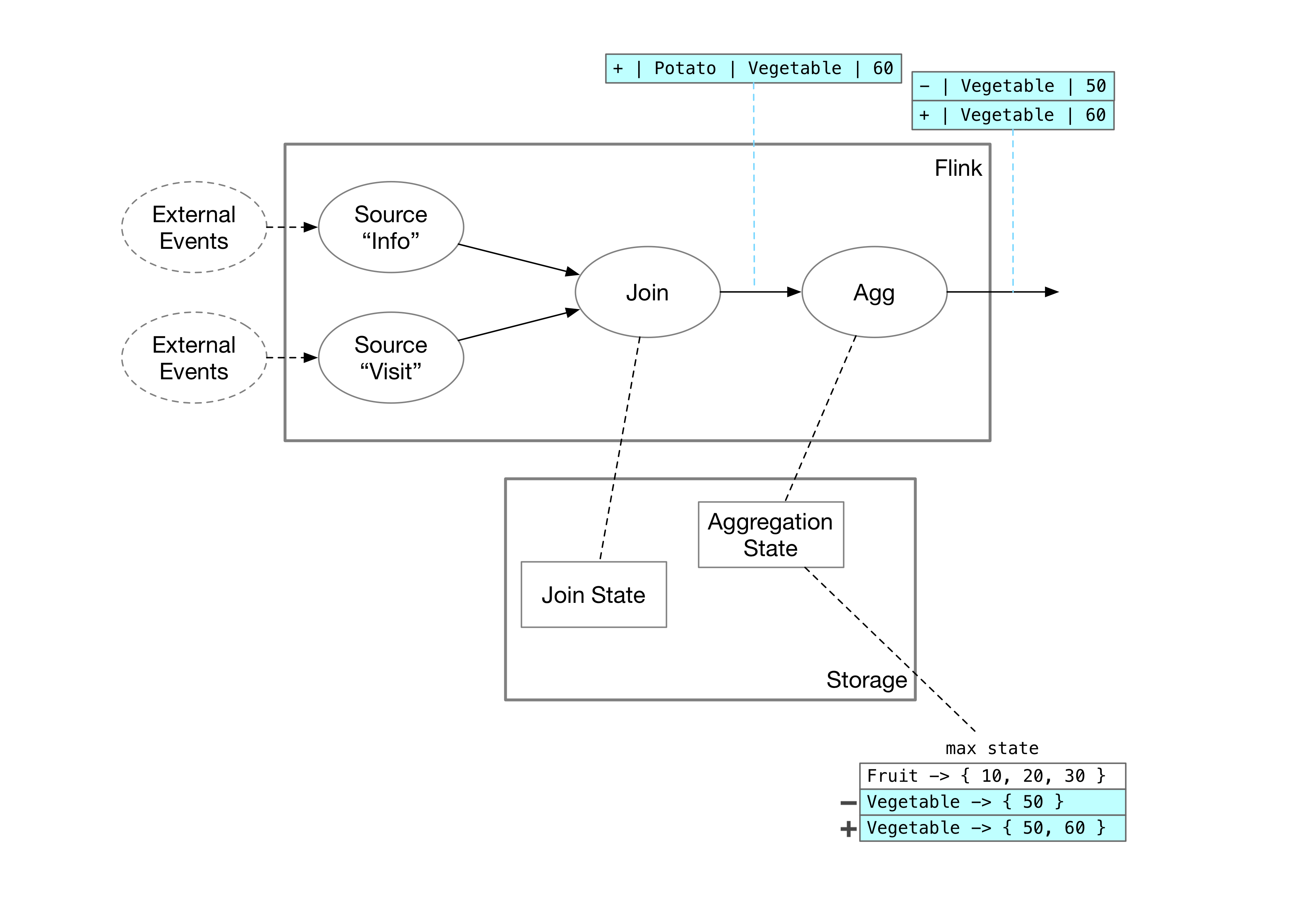
但对于 max 状态来说,我们就不能只记录最大的那个值了。如果上游发来了一条 delete 消息,max 状态需要把第二大的值作为新的最大值发给下游。如果只记录最大值,删掉最大值以后就没法知道第二大的值是多少。因此,Agg 算子需要存储一个 group 对应的完整数据。比如在我们的例子里,AggMaxState 现在存的数据有:
Fruit -> { 10, 20, 30, 40 }
Vegetable -> { 50 }上游 Join 算子发来一条插入 Potato, Vegetable, 60 的消息,Agg 算子会更新自己的状态:
Fruit -> { 10, 20, 30, 40 }
Vegetable -> { 50, [60] }并把 Vegetable 这一组的更新发给下游。
DELETE Vegetable, 50
INSERT Vegetable, 60整个过程如下图所示:
总结
存储完整状态的流系统通常来说有这么几个特点:
- 流计算图上单向传递数据变更的消息 (添加/删除)。
- 流算子维护、访问自己的状态;与此同时,在多路 Join 的时候,存储的状态可能重复。后文在介绍共享状态时也会详细介绍这一点。
Shared State - 算子之间共享状态
我们以 Differential Dataflow (Materialize 下面的计算引擎) 的 Shared Arrangement 为例介绍这种共享状态的实现。下文将使用 DD 简称 Differential Dataflow。
DD 的 Arrange 算子与 Arrangement
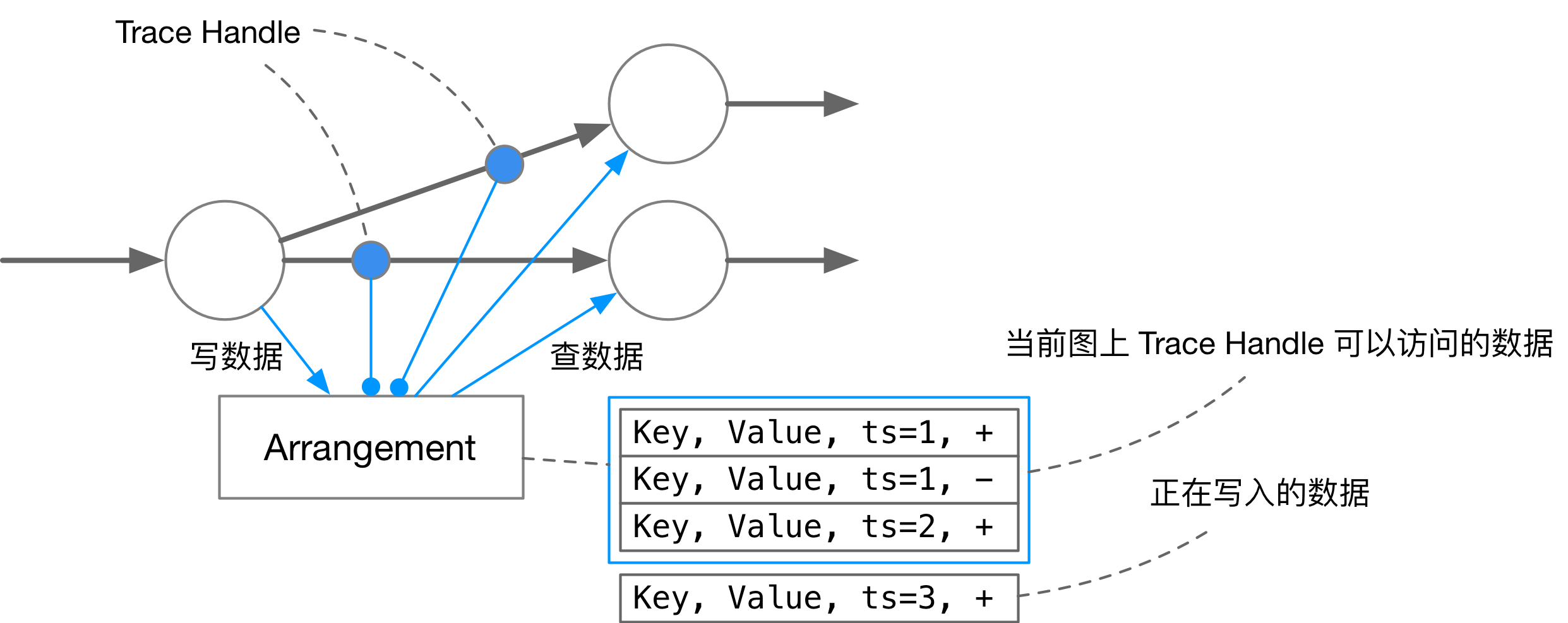
DD 使用 Arrangement 来维护状态。简单来说,Arrangement 是一个支持 MVCC 的 key-value map 数据结构,存储 key 到 (value, time, diff) 的映射。在 Arrangement 上可以:
- 通过 handler 任意查询某个时间点 key-value 的映射关系。
- 查询某一个 key 在一段时间内的变更情况。
- 指定查询的水位,后台合并或删除不再使用的历史数据。
DD 中大部分算子都是没有状态的,所有的状态都存储在 Arrangement 里。Arrangement 可以使用 Arrange 算子生成,也可以由算子 (比如 Reduce 算子) 自己维护。在 DD 的计算图上,有两种消息传递:
- 数据在某一时刻的变更
(data, time, diff)。这种数据流叫做 Collection。 - 数据的快照,也就是 Arrangement 的 handler。这种数据流叫做 Arranged。
DD 中每个算子的对自己的输入输出也有一定的要求,比如下面几个例子:
- Map 算子(对应 SQL 的 Projection)输入 Collection 输出 Collection。
- JoinCore 算子 (Join 的一个阶段) 输入 Arranged 输出 Collection。
- ReduceCore 算子 (Agg 的一个阶段) 输入 Arranged 输出 Arranged。
之后我们会详细介绍 DD 中的 JoinCore 和 ReduceCore 算子。
从 Differential Dataflow 到 Materialize
Materialize 会将用户输入的 SQL 查询转换为 DD 的计算图。值得一提的是,join, group by 等 SQL 操作在 DD 中往往不会只对应一个算子。我们顺着消息的流动,看看 Materialize 是如何存储状态的。
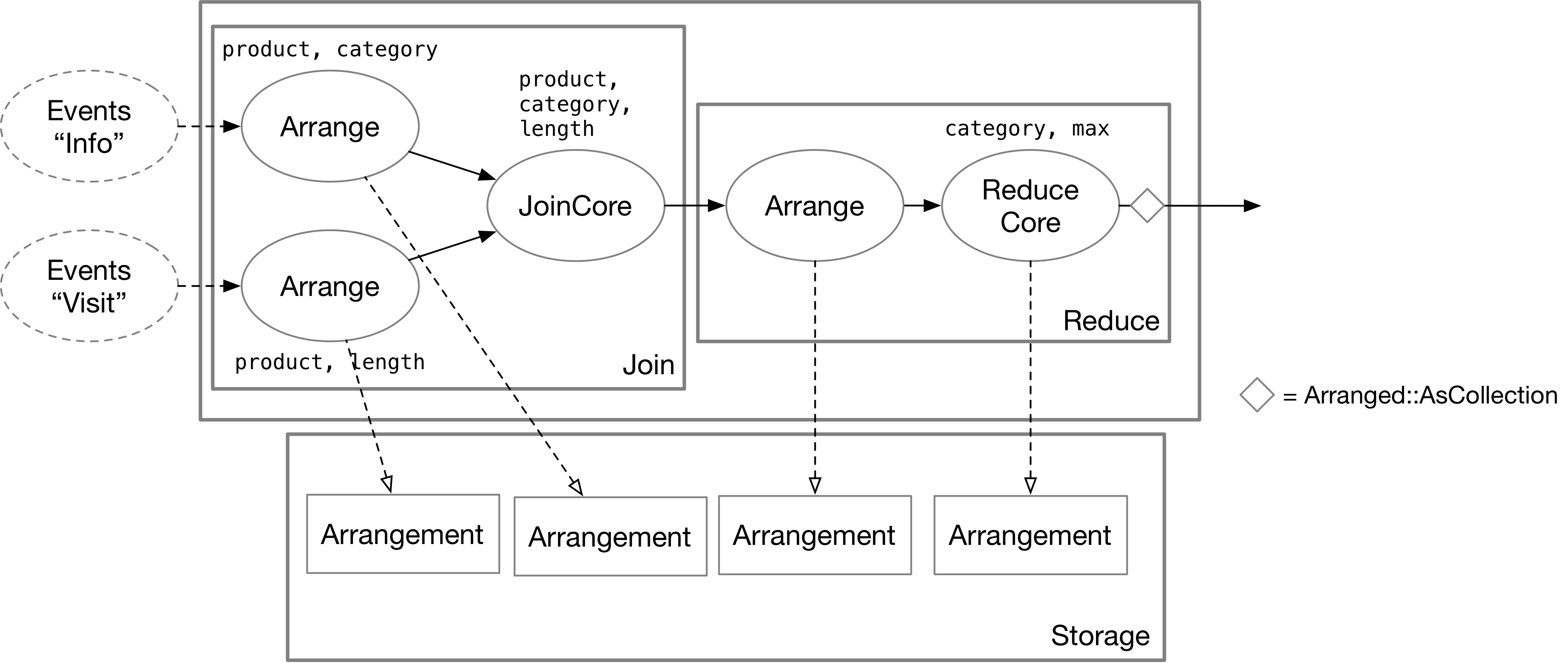
Join State 的存储
SQL 的 A Join B 操作在 DD 中对应三个算子:两个 Arrange 和一个 JoinCore。Arrange 算子根据 join key 分别持久化状态两个 source 的状态,以 KV 的形式存储在 Arrangement 中。Arrange 算子对输入攒批后,将 TraceHandle 发给下游的 JoinCore 算子。实际的 Join 逻辑在 JoinCore 算子中发生,JoinCore 不存储任何状态。
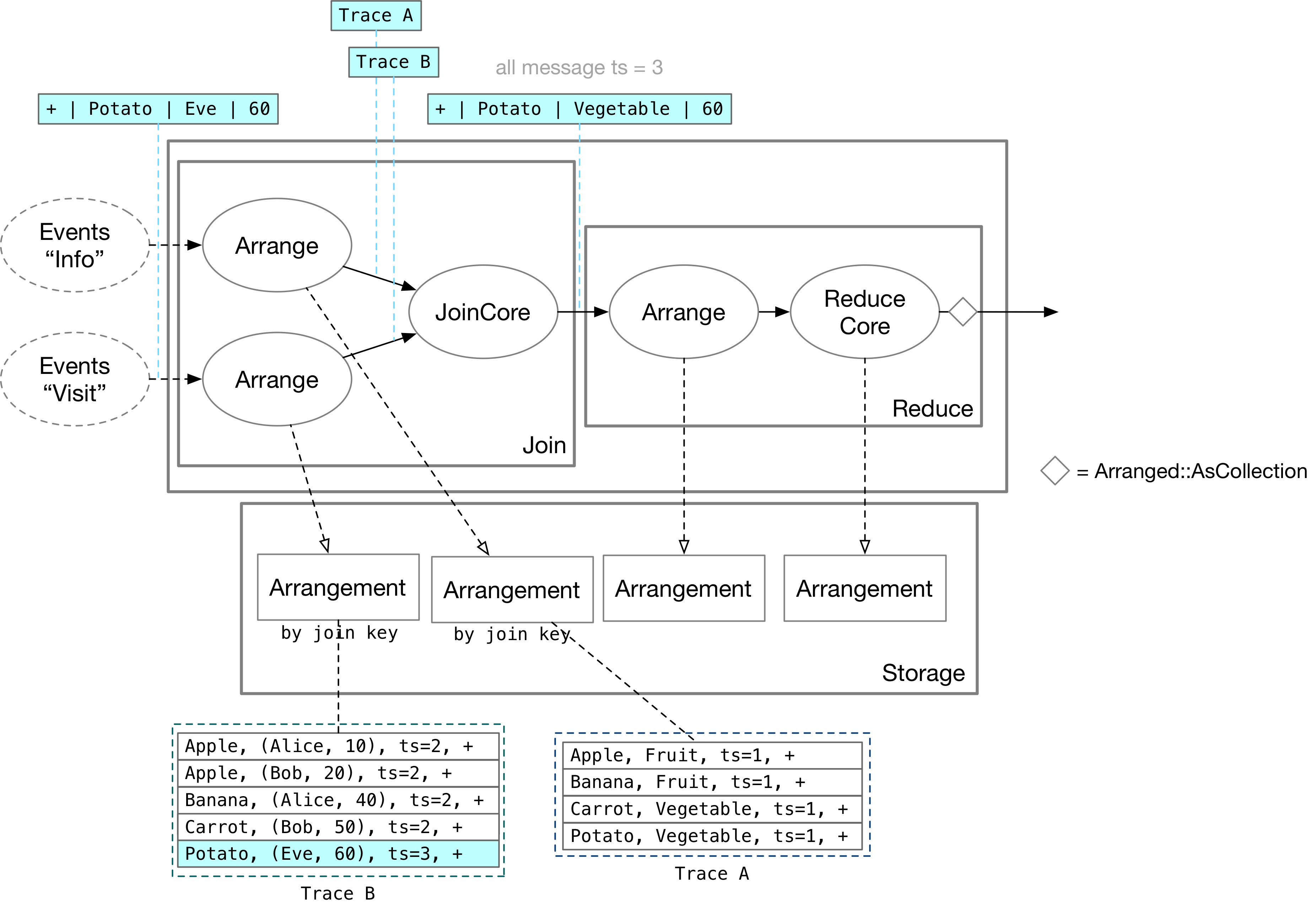
如上图所示,现在 Visit 侧来了一条更新:Eve 对着 Potato 看了 60 秒。JoinCore 算子通过 Trace B 访问到这条更新,并向另一侧的 Trace A 查询 product = Potato 的行,匹配到 Potato 是一种蔬菜,往下游输出 Potato, Vegetable, 60 的更改。
Reduce 状态的存储
DD 中 SQL Agg 算子对应 Reduce 操作。Reduce 中又包含两个算子:Arrange 和 ReduceCore。Arrange 算子根据 group key 存储输入数据,ReduceCore 算子自己维护一个存储聚合结果的 Arrangement,而后通过 as_collection 操作将聚合结果输出成一个 collection。
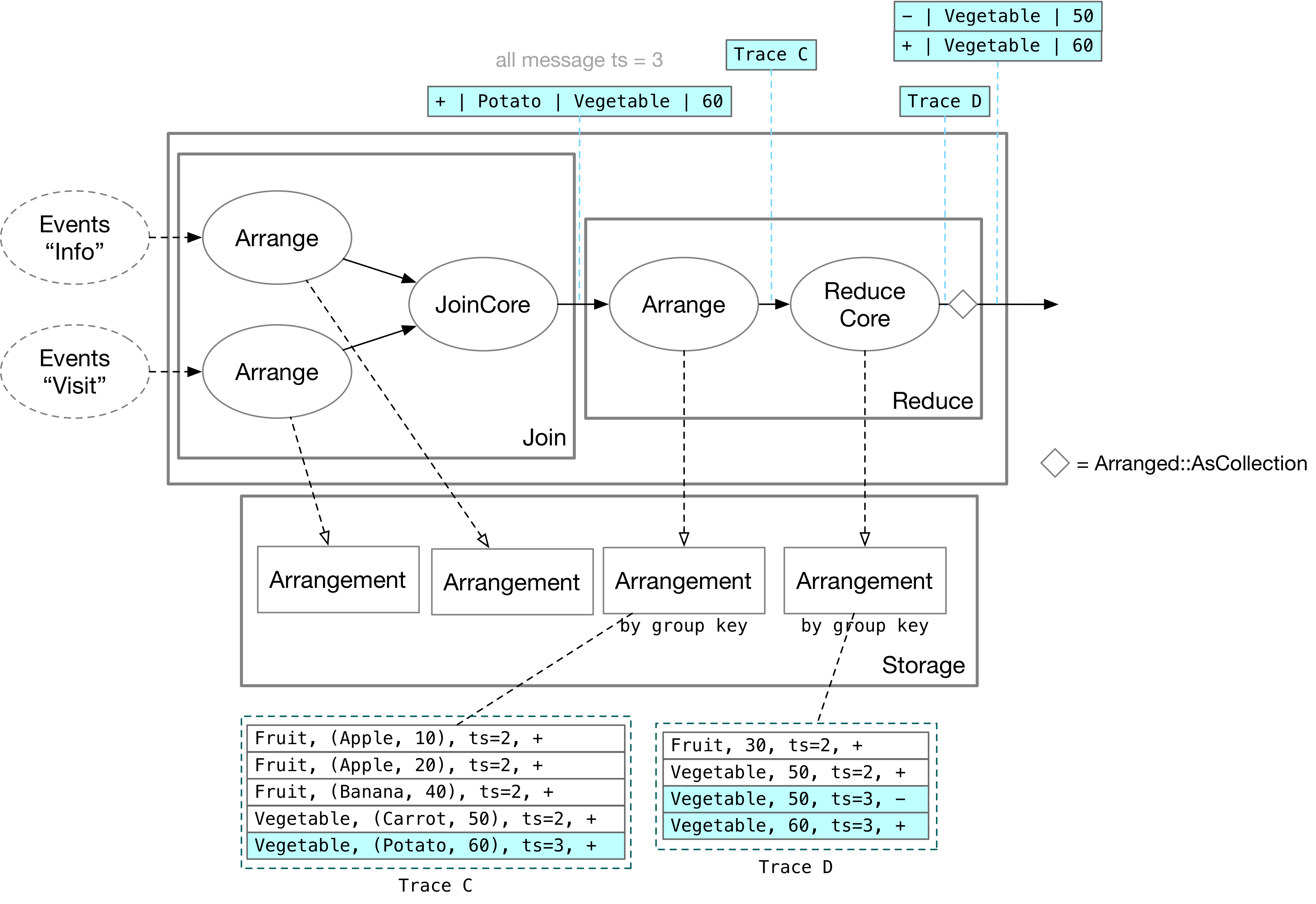
Join 的更新来到 Reduce 算子后,先被 Arrange 算子根据 group key 存储在 Arrangement 中。ReduceCore 收到 Trace C 后,将 key = Vegetable 的行全部扫描出来,并求最大值,最后将最大值更新到自己的 Arrangement 中。Trace D 经过 as_collection 操作后,即可输出为数据更新的形式,变成其他算子可以处理的信息。
更方便的算子状态复用
由于 DD 中存储状态的算子和实际计算的算子是分开的,我们可以利用这个性质做算子状态的复用。
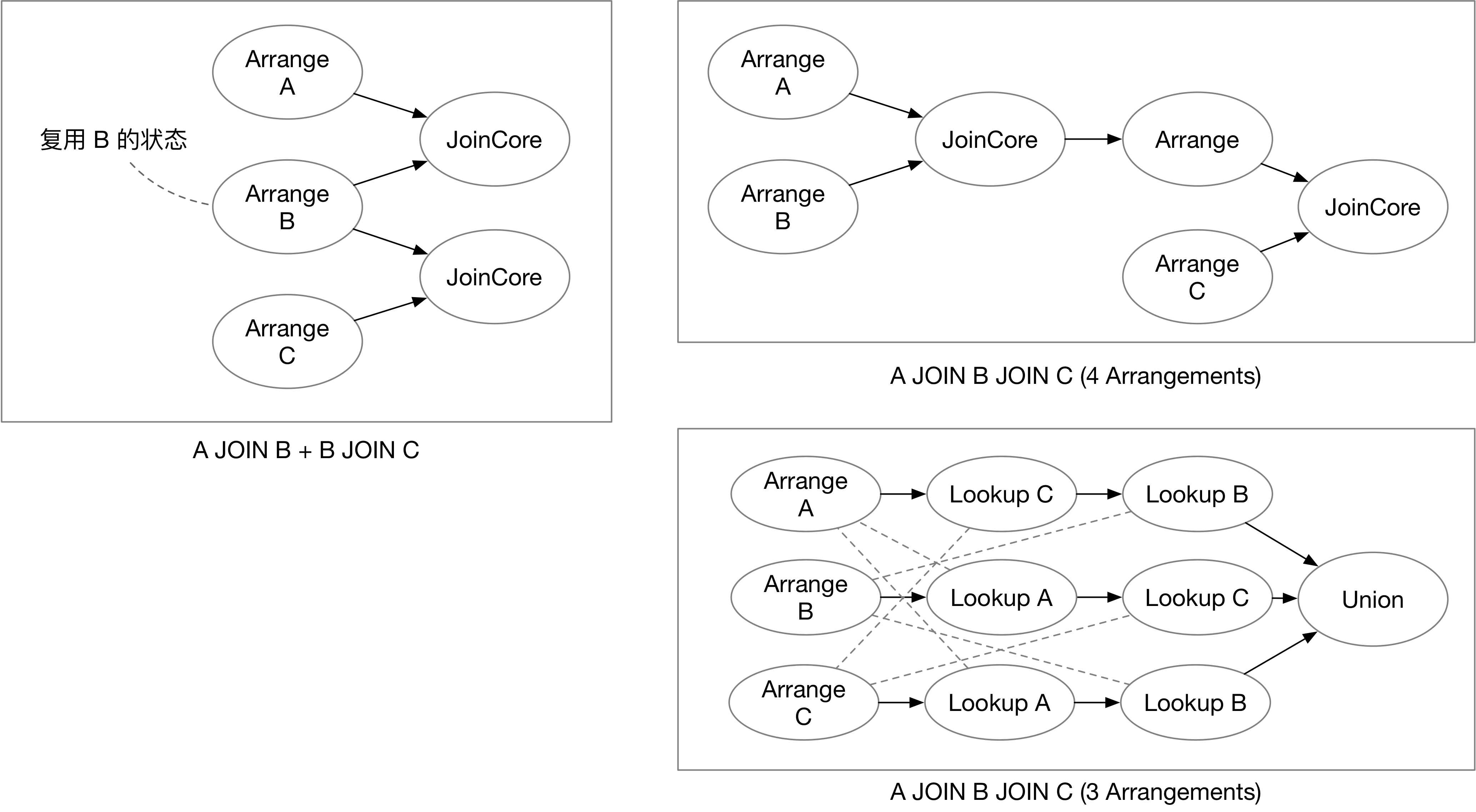
比如用户想要同时查询 A JOIN B 和 B JOIN C,在 DD 中,一种可能的计算图就是生成三个 Arrange 算子和两个 JoinCore 算子。相比于存储完整状态的流处理系统,我们可以避免 B 的状态被存两遍
另一个例子是多路 Join,比如 SELECT * FROM A, B, C WHERE A.x = B.x and A.x = C.x。在这个例子中,如果使用 JoinCore 算子来生成计算图,状态还是有可能重复,一共需要生成 4 个 Arrangement。
Materialize 的 SQL Join 除了被转换为上文所述 DD 的 JoinCore 算子之外,也有可能转换为 Delta Join。如图所示,我们只需要分别生成 A, B, C 的 3 个 Arrangement,然后使用 lookup 算子查询 A 的修改在 B C 中对应的行(其他两个表的修改亦然),最后做一个 union,即可得到 Join 的结果。Delta Join 可以充分利用已有的 Arrangement 进行计算,大大减小 Join 所需的状态存储数。
远程访问状态的开销
在流系统中,计算中间产生的数据往往无法全部放在一个结点上;与此同时,同一个执行计划中的节点,也会有很多并行度。比如下面这个两表 Join 的例子。两个表 A、B 的 Arrangement 可能分别在两个结点上产生 (Node 1, 2),然后同时用两个结点分别对其中一部分数据做 Join。
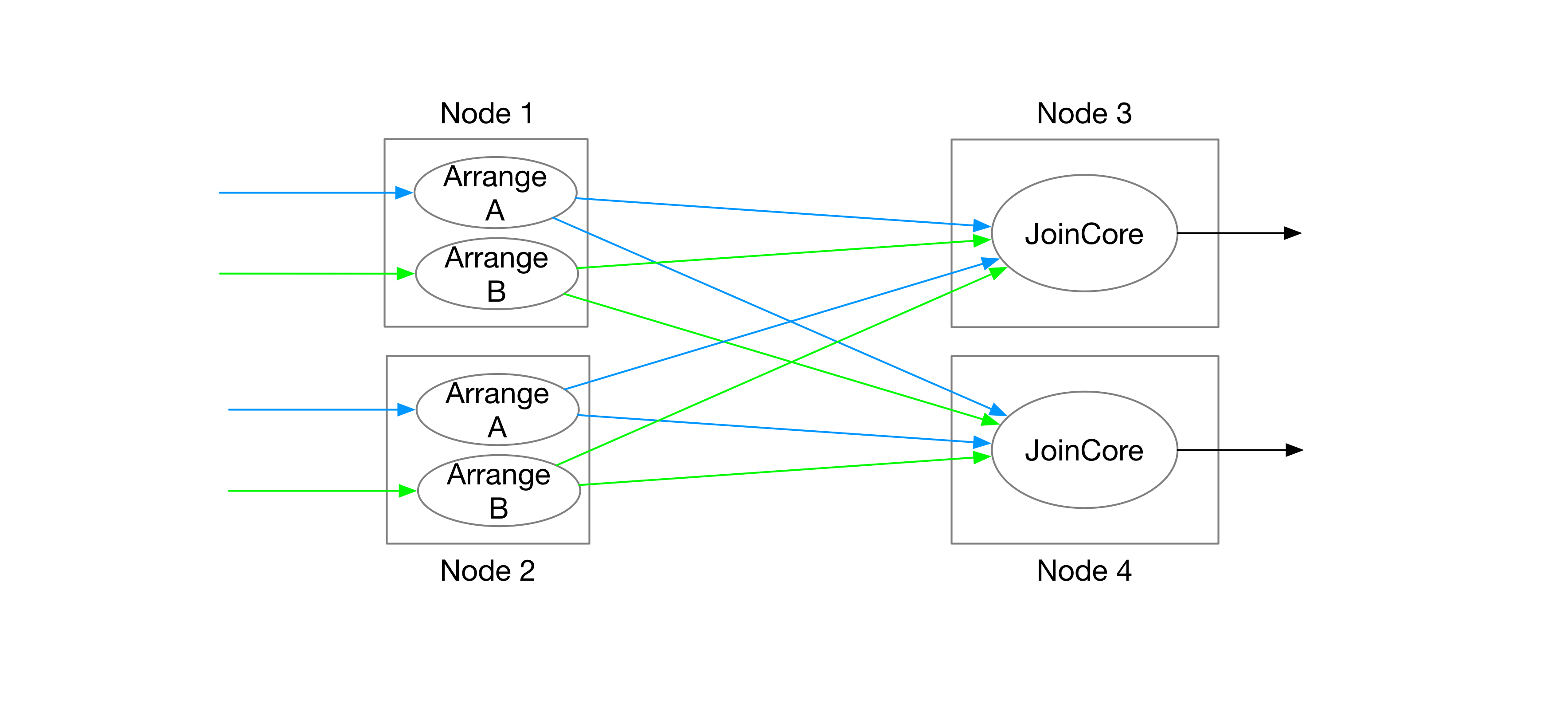
在这个情况下,DD 中势必会发生远程访问 Arrangement 的问题。由于算子完全没有内部状态,JoinCore 每处理一行都需要一次远程访问,查找 join key 对应的数据。总的来说,Arrange 和计算放在两个结点上会大大增加计算的延迟,放在一个结点上又无法充分利用分布式系统的资源,这是一个比较矛盾的地方。
总结
在共享状态的流处理系统中,算子的计算逻辑和存储逻辑被拆分到多个算子中。因此,不同的计算任务可以共享同一个存储,从而减少存储状态的数量。如果要实现共享状态的流处理系统,一般会有这样的特点:
- 流计算图上传递的不仅仅是数据的变更,可能还会包括状态的共享信息(比如 DD 的 Trace Handle)。
- 流算子访问状态会有一定的开销;但相对而言存储完整状态的流计算系统而言,整个流计算过程中由于状态复用,存储的状态数量更小。
Partial State - 算子只存储部分信息
在 Noria (OSDI ‘18) 这一系统中,计算不会在数据源更新信息时触发,流处理算子并不会保存完整的信息。
比如,如果用户在之前创建的视图上执行:
SELECT * FROM result WHERE category = "Vegetable"执行这条 SQL 的时候,才会触发流系统的计算。计算过程中,也只计算 category = "Vegetable" 相关的数据,保存相关的状态。下面将以这条查询为例,说明 Noria 的计算方式与状态存储。
Upquery
Noria 的各个算子仅存储部分数据。用户的查询可能直接击中这个部分状态的缓存,也有可能需要回溯到上游查询。假设现在所有算子的状态都为空,Noria 需要通过 upquery 来递归查询上游算子的状态,从而得到正确的结果。
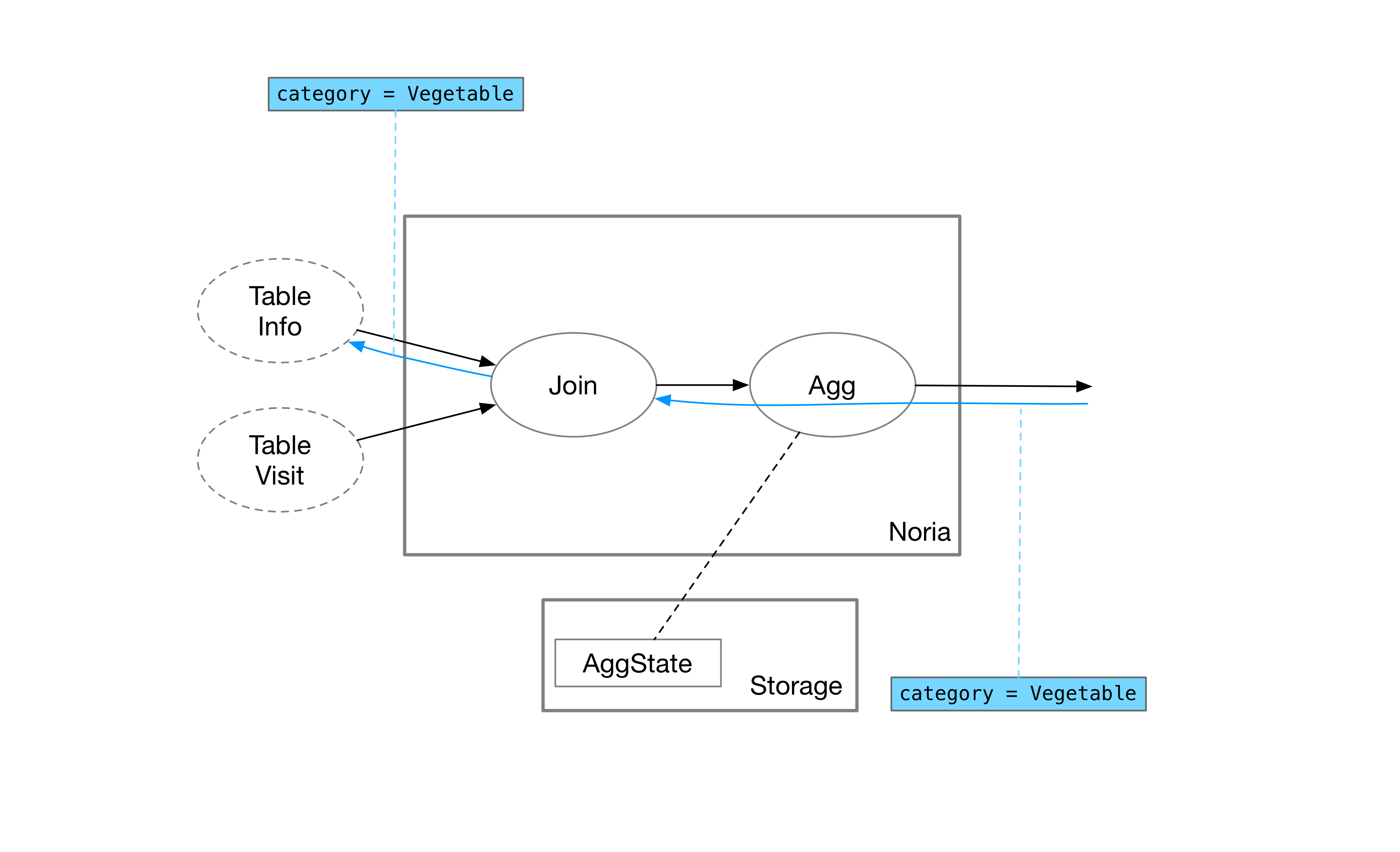
用户向流计算引擎查询 category = "Vegetable" 的最大值。Agg 算子为了计算出它的结果,需要知道所有 category 为蔬菜的记录。于是,Agg 算子将这个 upquery 转发到上游 Join 算子。
Join 算子要得到蔬菜对应的所有信息,需要向两个上游表分别查询情况。category 属于 Info 表的列,因此,Join 算子将这条 upquery 转发给 Info 表。
Join 算子的实现
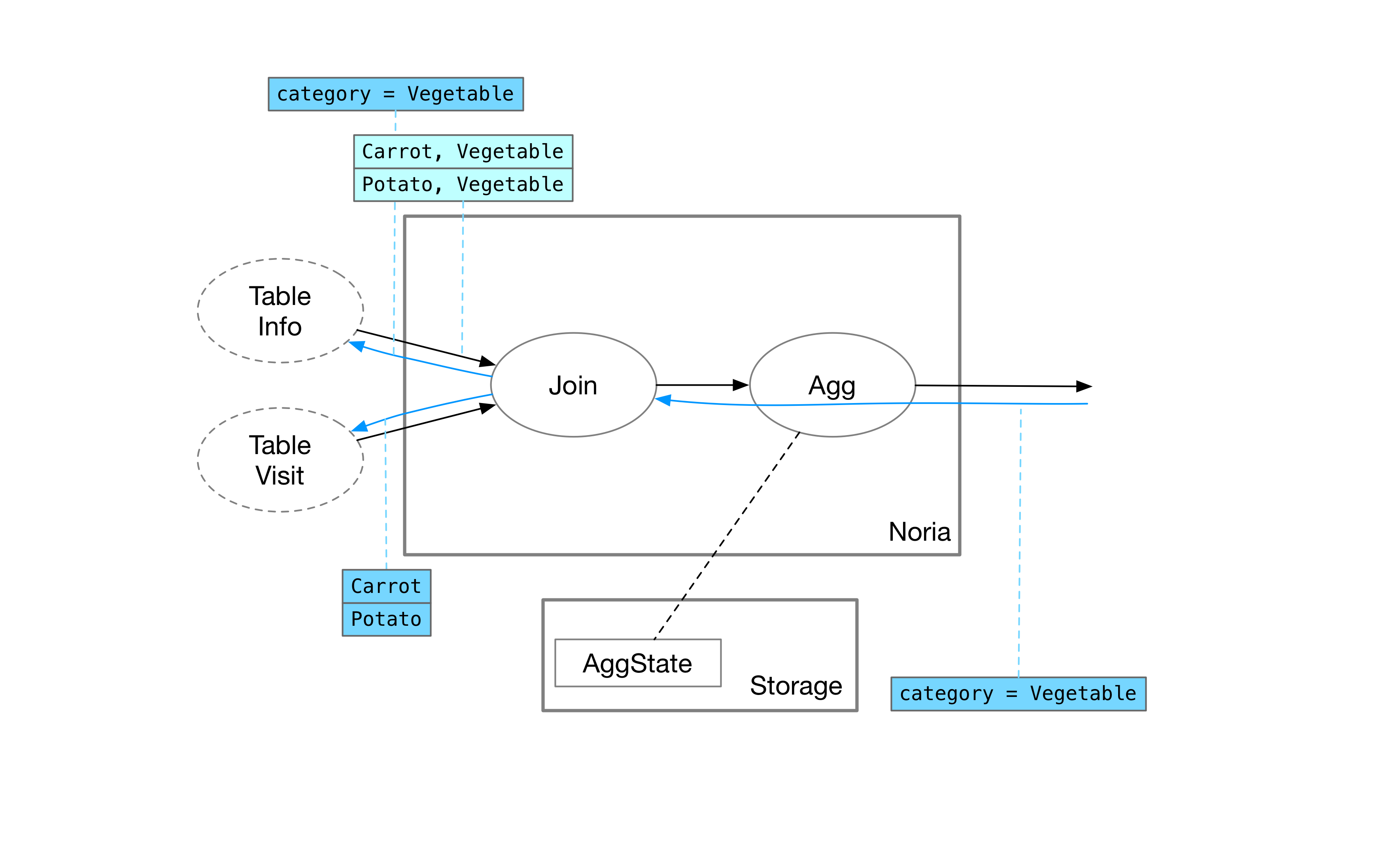
Info table 返回蔬菜分类下的所有产品后,Join 算子会再发一个 upquery 给另一边 Visit table,查询胡萝卜、土豆对应的浏览记录。
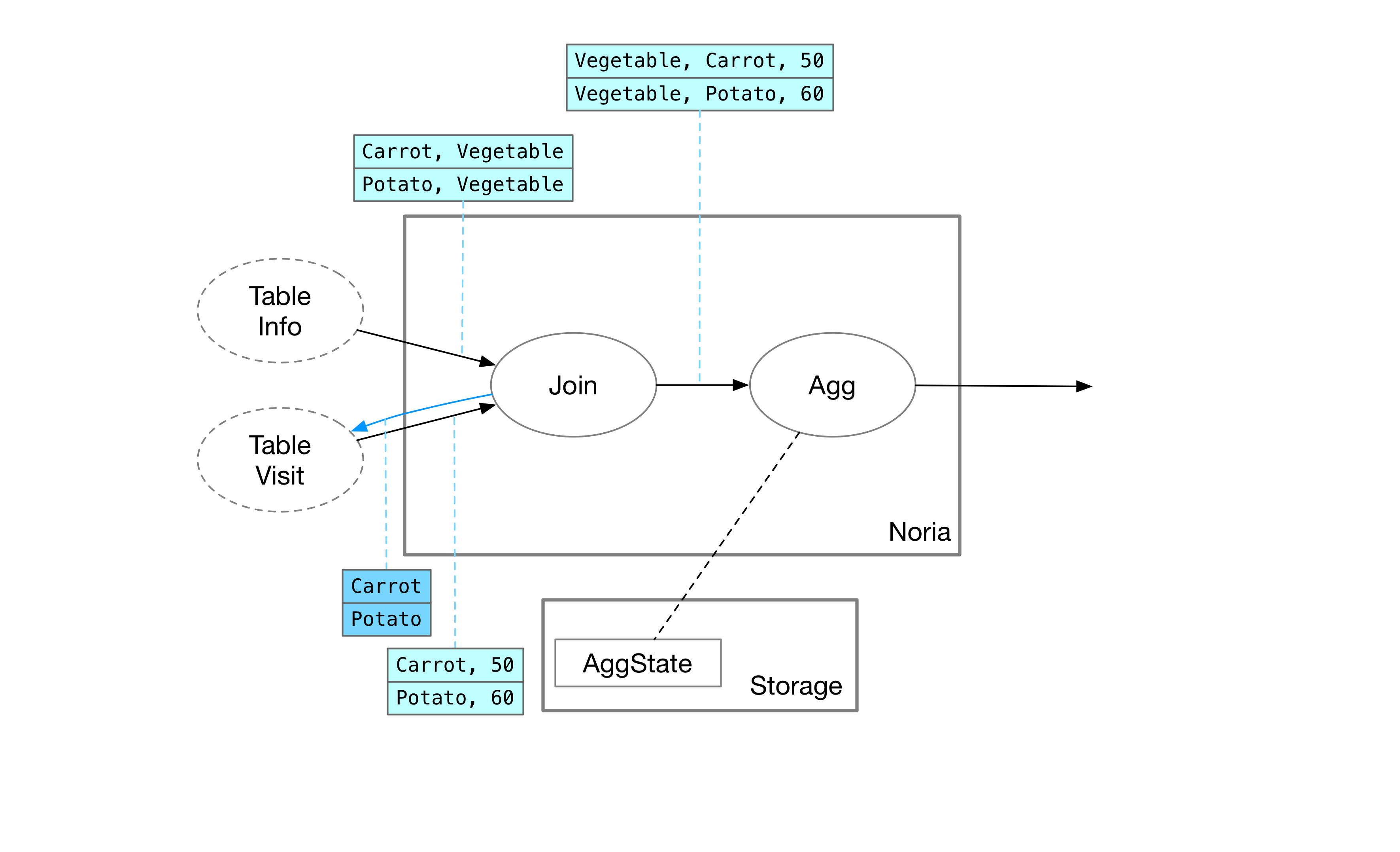
Visit table 返回对应记录后,Join 算子就可以根据两次 Upquery 的输出计算出 Join 结果了。
在 Noria 中,Join 算子无需保存任何实际状态,仅需要记录正在进行的 upquery 即可。
Agg 算子的实现
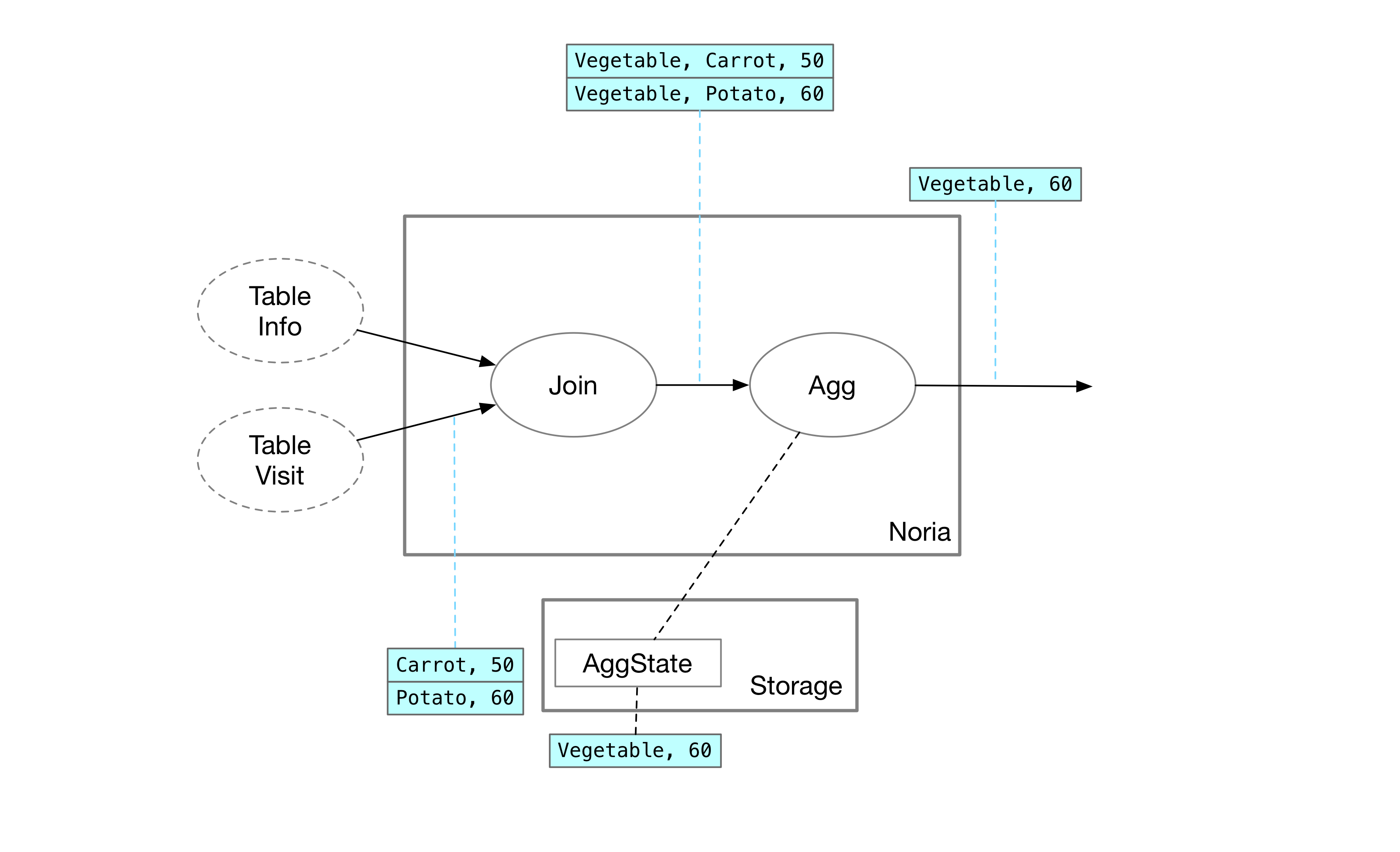
数据来到 Agg 算子后,Noria 将直接计算出最大值,并将最大值存储在算子的状态中。在前文所述的系统里,Agg 算子的状态需要保存完整的数据(水果的所有浏览记录、蔬菜的所有浏览记录)。Noria 只需要缓存用户请求的状态,因此在这个请求中只要记录蔬菜的记录。与此同时,如果上游发生了删除操作,Noria 可以直接将蔬菜对应的行删除,以便之后重新计算最大值。因此,在存储部分状态的系统中,也无需通过记录所有值的方法回推第二大的值——直接清空缓存就行了。
总结
存储部分状态的流处理系统通过 upquery 的方式实时响应用户的请求,在本文所述的实现中,所需要存储的状态数最少。它一般有以下特点:
- 计算图的数据流向是双向的——既可以从上游到下游输出数据,也可以从下游到上游发 upquery。
- 由于需要递归 upquery,计算的延迟可能比其他状态存储方式略微大一点。
- 数据一致性比较难实现。本文所述的其他存储方法都可以比较简单地实现最终一致;但对于存储部分状态的系统来说,需要比较小心地处理更新和 upquery 返回结果同时在流上传递的问题,对于每个算子都要仔细证明实现的正确性。
- DDL / Recovery 非常快。由于算子里面的信息都是按需计算的,如果用户对 View 进行增删列的操作,或是做迁移,都可以直接清空缓存分配新节点,无需代价较高的状态恢复。
最后对比一下所有的状态存储方式所对应的流处理系统特征:
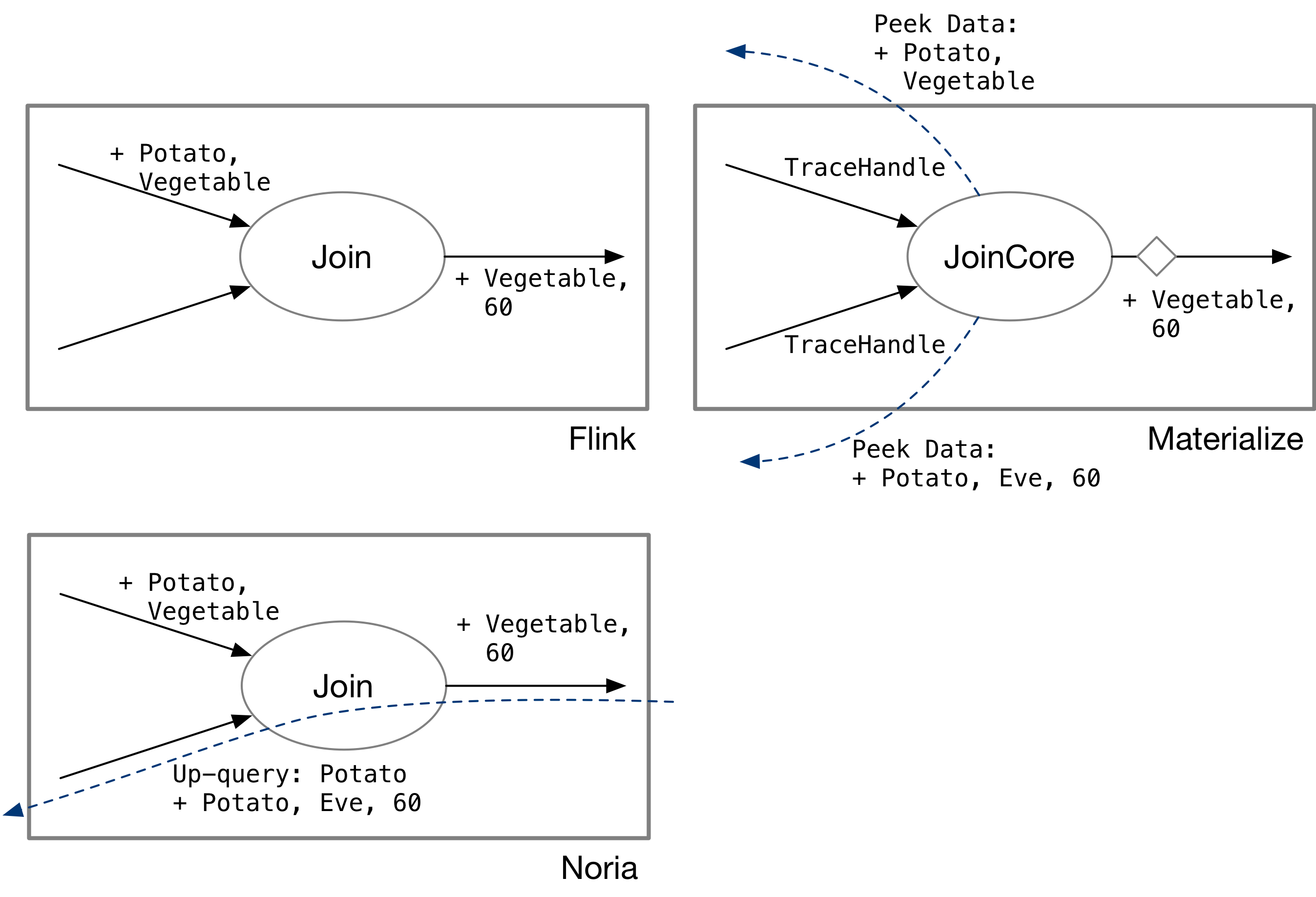
- 存储完整状态 (以 Flink 为例):流上传递数据。
- 共享状态存储 (以 Materialize / DD 为例):流上传递数据和 snapshot。
- 存储部分状态 (以 Noria 为例):流上传递数据,流上双向都有消息。
Reference
- Apache Flink
- Flink SQL
- Materialize
- Joins in Materialize
- Maintaining Joins using Few Resources
- differential-dataflow
- Noria
写这篇文章时,我也大量阅读了 Differential Dataflow 和 Noria 的源代码。如果有具体实现上的问题,也欢迎交流。
欢迎在这篇文章对应的 Pull Request 下使用 GitHub 账号评论、交流你的想法。