A Year in BusTub
Table of Contents
Introduction
It has been almost a year since I started working on BusTub, the educational database system for CMU 15-445/645 (Database System) course. Significant transformations have taken place in the system, and it is an excellent time to revisit all these things and set the next milestone for the system.
Back to where it started, I had not imagined working on BusTub until an email popped up in my mailbox: “Do you want to be a TA for 15-445 this fall?“. It was from Andy Pavlo shortly after I accepted the MSCS offer from CMU.
I heard rumors that CMU courses are super challenging, and I was wondering if I would have enough time to participate in the course as a TA in my first semester at CMU. After I explained my concerns, Andy hired me as a system developer so that I could focus on coding without worrying about all the other stuff, and I went ahead to land big features to the codebase. I created pull requests very quickly and the review queue soon accumulated. Wan spent too much time reviewing my PRs that Andy asked him to focus on his research. Yuchen took over the mission and got all remaining PRs merged. Interestingly, when the former TA Abi returned from TileDB in spring 2023, she complained that the codebase had changed too much since her last time as a TA. And lastly, I discovered that the course load at CMU is not as hard as I thought it to be, so I decided to host office hours and became more like a TA for the second half of the fall semester.
On the one hand, we got feedback from students that the benchmarks and optimizations were fun to work on, and they tried to beat each other on the leaderboard. On the other hand, students complain that the course is more challenging than their senior alumina has told them. But overall, BusTub is becoming more like a SQL database system in that people can learn and connect deeply with what the database industry is doing, which is a good starting point for anyone pursuing a database career or to understand more about system programming.
New Features
SQL
In the summer of 2022, the first time I looked at the BusTub repo, I was surprised that BusTub does not support SQL, while the entire course is based on relational database (and SQL)! No SQL support is a big problem, as students cannot learn how a database system works end-to-end by solely staring at the query plans. Therefore, I took the initiative to add a query processing layer to BusTub. With some initial investigation done by Garrison, we realized that the easiest way to integrate SQL is to do it from scratch instead of plugging in some kind of query processing layer from other systems. There was a branch that made BusTub the query backend of PostgreSQL, but it is far from completion. I went in the DuckDB way that only used the PostgreSQL parser and wrote the rest of the query processing layer (i.e., binder, planner, optimizer) myself.
The addition of the query processing layer went on par with the course. I added many new things to the codebase while students did homework based on that! Doing them in parallel means that I need to be extra careful not to touch the source code files that students edit or will potentially conflict with their solution. The plan was for students to use SQL to test their executor implementation in Project 3. I started working on the codebase in late August, and Project 3 would begin in mid-October, so I only have one and a half months to deliver the result. If it works, students can work with SQL in fall 2022. If it fails, we can only have that in the following semester. The schedule was tight, but we shipped SQL support in the end.
It did not take us a long time before making our first SQL SELECT 1 work, probably two weeks or so, with a hand-crafted binder and planner. After that, I spent another two weeks integrating the query processing layer with joins, aggregations, insertions, sorts, and create statements — all the executors we support in BusTub. The progress went so well that we still had several weeks before rolling out the query execution project. Therefore, I made more crazy things in my mind come to life.
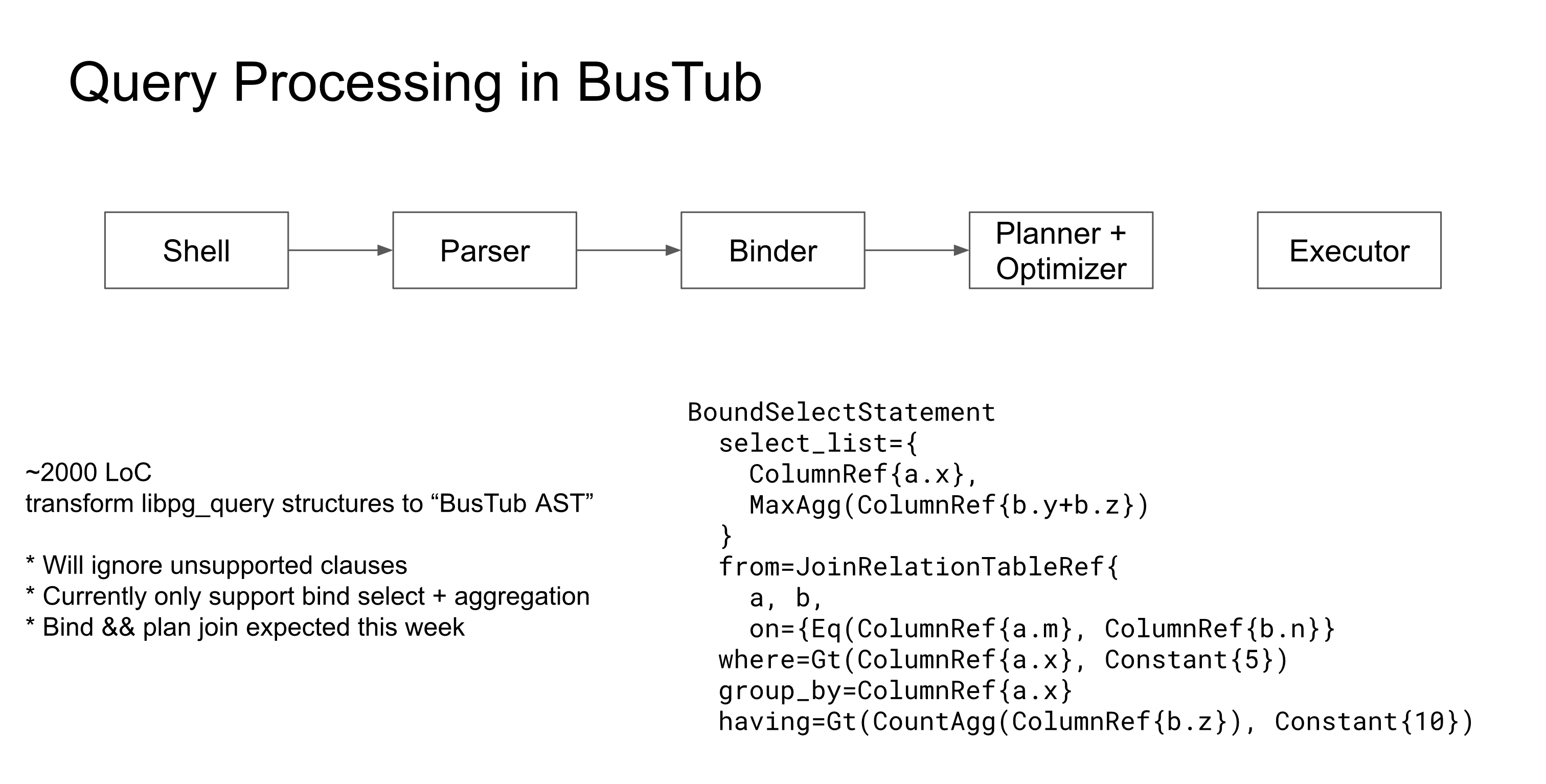
Query Optimizer
Optimizer was outside my original plan, and I thought only to have a planner that directly transforms SQL into plan nodes. To make the query processing project more interesting, especially for those with a strong interest in database systems, I decided to spend some time adding a rule-based optimizer to the system so that students can optimize their system not just by making their executor more efficient, but to rewrite the query plan.
I typically view a database system in 3 layers:
- The query processing layer, which takes SQL in and does transformations.
- The query execution layers contain a lot of query executors.
- The storage layer, which stores data and serves read requests.
Generally, optimizing the lower part of the system (i.e., storage) is hard, but it benefits all kinds of query patterns. Optimizing the query processing layer is much easier, as people generally handle various “edge cases”, which brings considerable benefits for a small set of queries. For example, when working in my previous company, I usually took one TPC-H query, looked at the plan, and saw how to make this query faster by having a better plan. If a query optimizer is not producing an optimal plan, it does not matter how quickly the query executor and the storage is. Therefore, having the chance to optimize the system top-to-down will be an excellent learning experience for students.
And that is what students see in project 3 — three hand-crafted SQL queries to be optimized. Optimizing both the query plan and the executor implementation is the only way to get a top rank on the leaderboard.
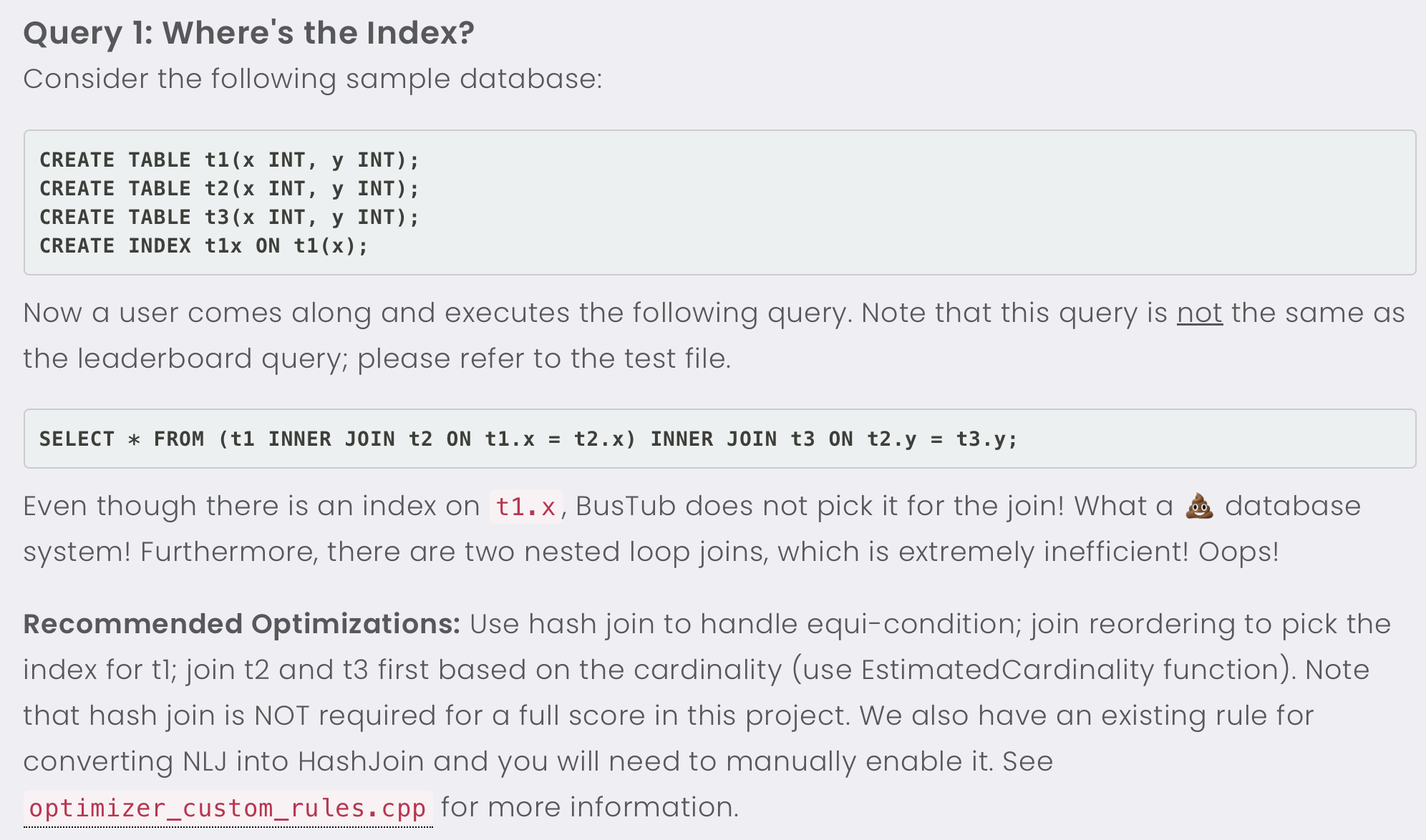
One fun fact: I did not implement any optimizations in the reference solution. I was always surprised by what our students could develop when I looked into their code that ranked top on the leaderboard.
Web Shell
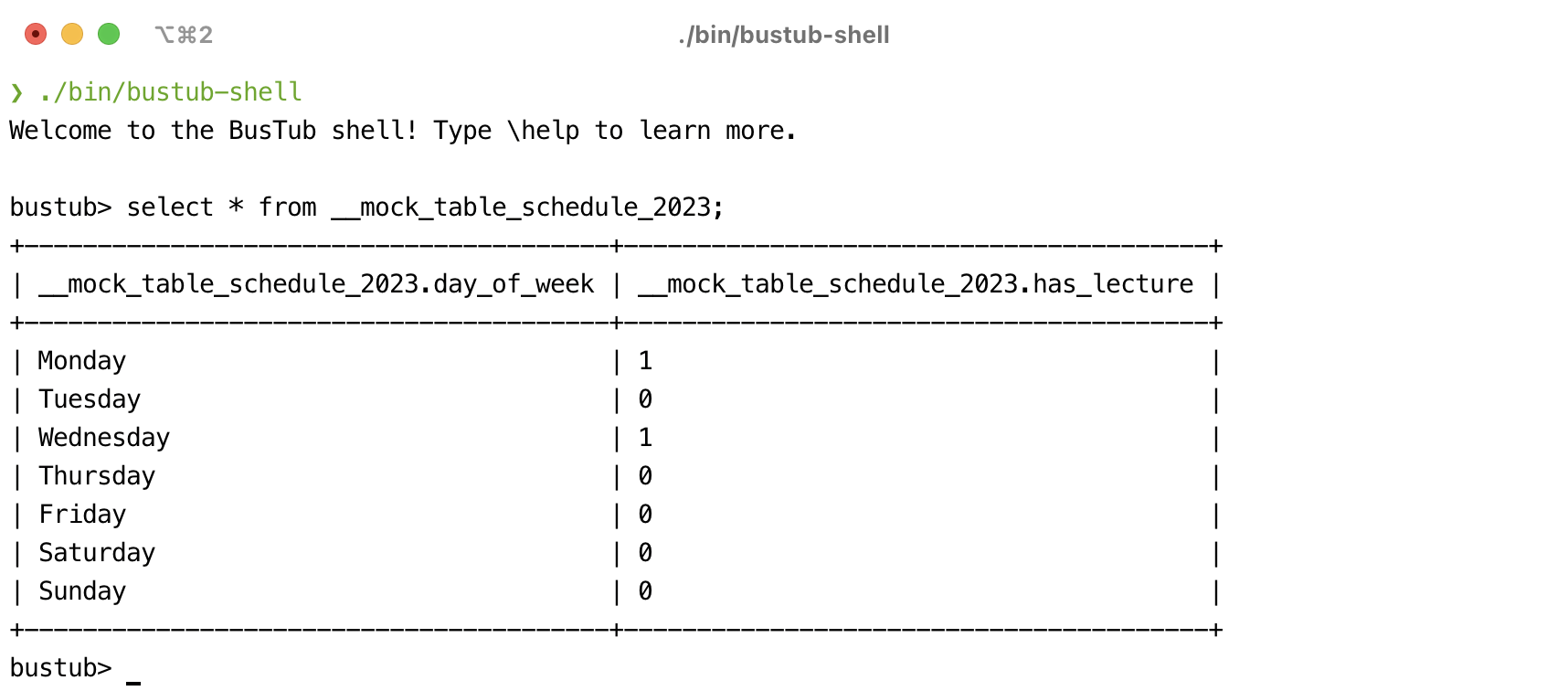
Another crazy thing I have done is to bring BusTub to the browser. We make it possible using Emscripten, which compiles the C++ codebase to WASM and adds polyfills for file system operations. The BusTub codebase is relatively simple, and we only need to solve some symbol conflicts to make it work. With the BusTub web SQL shell set up, students can try the entire system before starting their project. Besides the SQL shell, we also compiled our B+ Tree implementation to WASM. We visualized the B+ tree structure in the browser using GraphViz (thanks Ricky Xu for the original version of the dot file generator) so that students could test their understanding and see how the B+ tree splits and merges in their browser.
SQLLogicTest
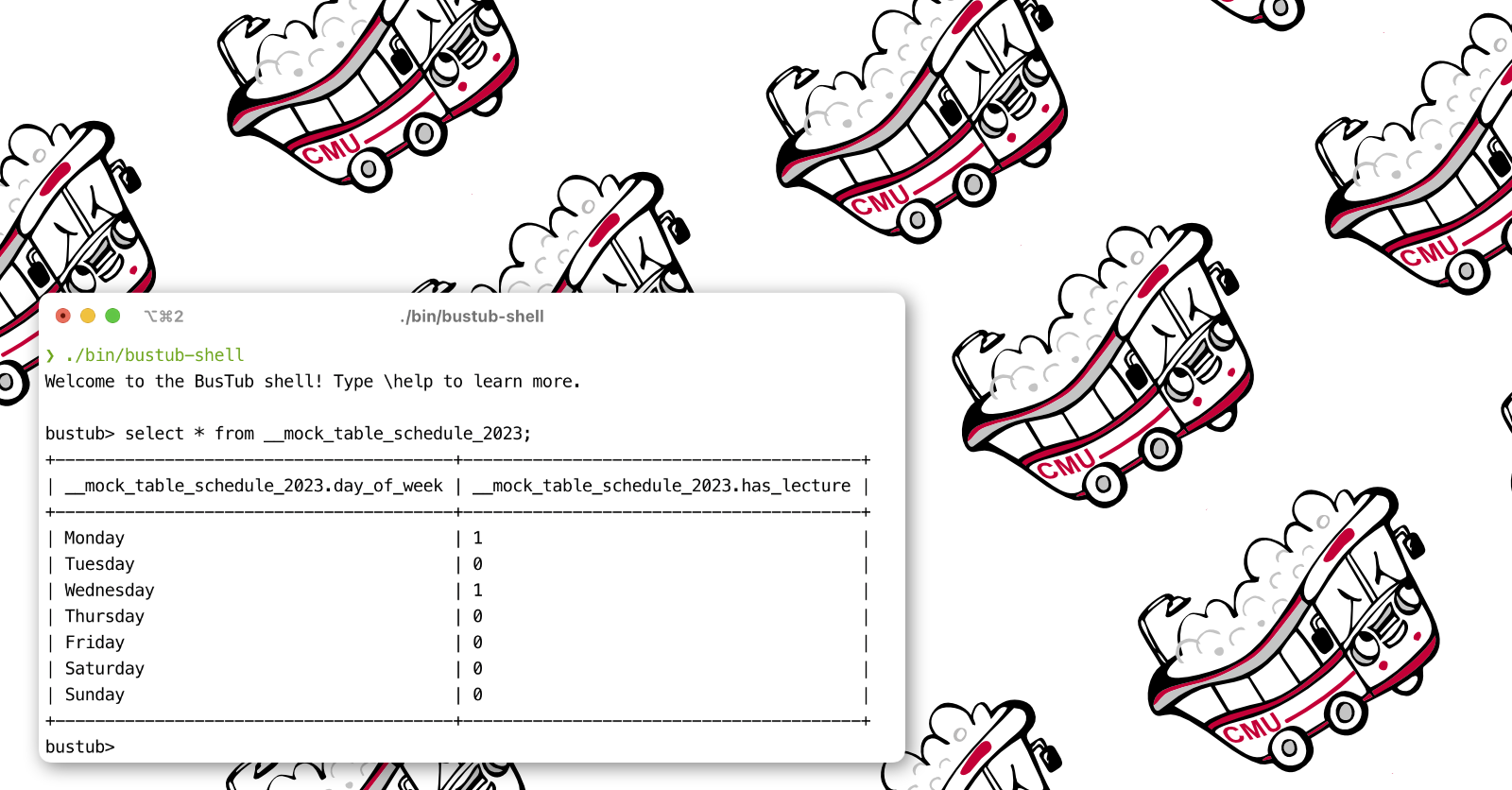
With the new query processing layer built in BusTub, we introduced a new way of testing — SQLLogicTest. Originating from SQLite, this test format has been adapted in many projects like Apache Datafusion.
An example of this format:
query rowsort
select github_id from __mock_table_tas_2023;
----
abigalekim
arvinwu168
christopherlim98
David-Lyons
fanyuex2
Mayank-Baranwal
skyzh
yarkhinephyo
yliang412Minor Updates
Better Benchmarks
All leaderboard tests have been redesigned to ensure students focus on architectural changes instead of design hacks. It is well known that Gradescope is not stable in the case of computation-heavy things, causing some students working on leaderboard tests to submit 50-200 times to squeeze the best result from the same piece of code. With the new benchmark suites, students are expected to implement new algorithms and make significant architecture changes in their code to achieve better performance instead of simply changing some parameters in their code, sitting and hoping Gradescope would give some good results. For example, in Project 1, we added some latency to disk operations in the buffer pool manager benchmark. Therefore, students must find a way to issue parallel I/O requests to exploit throughput improvements.
New Project 0
Project 0 is a small project that students can finish in a few hours to get familiar with the codebase. Students will leverage this project to get hands-on experience with C++ and know if they have met the prerequisites of the course.
We have redesigned Project 0 to help students learn C++ from an actual project. I talked to some TAs at the end of fall 2022 that we should do something called “snapshot isolation Trie” based on copy-on-write techniques. It turned out that such copy-on-write structures are very suitable for people with a C background to pick up C++, as it involves many things that will be used throughout the course:
- C++ classes and derives
- templates
- mutex and concurrency safe code
- shared pointers and RAII
- writing test cases
- copy constructor and move constructor
Making B+ Tree Less Painful
The B+ tree project was known for its ridiculous difficulty before spring 2023. One of the main reasons that students cannot finish it is the misuse of buffer pool manager APIs and the wrong concurrency control scheme.
With the challenges in mind, we have redesigned the project to use PageGuard for manipulating a page from the buffer pool manager. If the user needs to access a page, they must acquire a guard from the buffer pool manager that pins the page in the memory. The pin count will automatically decrease when the guard goes out of scope, preventing students from making mistakes like forgetting to unpin a page or pinning a page multiple times in the code path.
ReadPageGuard guard = bpm_->FetchPageRead(root_page->root_page_id_);
guard.As<BPlusTreePage>()->IsLeafPage(); // do some operations...
guard.Drop();For concurrency control, most students did not fully understand how to handle the write operations that might create or delete the root page. Therefore, we store the pointer to the root page on a separate page called HeaderPage, which significantly simplifies the concurrency control part because all locks in the B+ tree index are page locks, and they can be handled in the same way now.
To ensure students implement lock crabbing correctly, we implemented a heuristic-based detection mechanism to identify possible wrong implementations, and TAs will manually review the code based on heuristics. We run a designed benchmark over students’ B+ tree code to see if the performance is the same in single-threaded and multi-threaded environments. If they are the same, then something is likely wrong.
Optimizations and Optimizations
With the new query optimizer, students can rewrite their queries into a more efficient form by writing and applying transformation rules that generate the most efficient query plan.
Furthermore, this enables students to optimize the system as a whole. In spring 2023, there is a query with an index scan over two index columns, and two filter conditions are applied on both columns. An optimal optimization would first need to convert such a query into an index scan. And then, design the B+ tree iterators so it is easy to skip some keys on the internal node.
Transactions in a Correct Way
The transaction manager project has been long known for buggy and flaky test cases. From the architecture perspective, the BusTub storage was not designed with concurrency control in mind, and the transaction manager was added sometime in 2018. Therefore, it needs to incorporate better with the rest of the system, and there are some correctness bugs to solve. I revisited the concurrency control thing and fixed several bugs that might cause correctness issues in spring 2023. Also, I reworked all test cases for the storage executors. As a result, we received fewer complaints on the concurrency control implementation in storage-related query executors this semester. However, there are still things to improve on the lock manager side.
What’s Next
The BusTub project has dramatically improved in the past year, and I still have some ideas in my mind that I want to implement. At some time, I imagined that we could have a Rust version of BusTub called RusTub, but I do not have that much time working on that, and we do not have enough TAs to support a course that builds on a language unfamiliar to most CMU students. Therefore, there are some small changes on the existing codebase we can look into. On the storage side, we can try the LSM index. The UCSB people adapted BusTub to their database course and asked their students to do an LSM index, which we could take and use at CMU. For the optimizer side, we could choose different things to optimize each semester. It was join-optimizations in fall 2022, indexes in spring 2023, and probably sorts in fall 2023.
Besides the regular minor improvements described above, two big things are there in my mind. One is to implement a complete MVCC concurrency control scheme in BusTub. The other is to extend the SQL support for correlated subqueries, window functions, and more data types. A few days ago, Runji added correlated subquery support for RisingLight (yet another educational database I maintain). I wish I could understand it soon and port some optimizer things to BusTub.
Working on BusTub has been a fascinating experience for me. I had been in the database industry for almost two years as an intern before I came to CMU. I learned much from these experiences by working on challenging database designs without officially taking a database course during my undergrad study. I started thinking, “What would I teach my past self to prepare myself for a database career”. For things I wished I had learned before I started my career, I added them to BusTub in a minimal and educative way.
Thanks for reading and feel free to leave your comments at GitHub.