My Final Semester in BusTub
Table of Contents
- Introduction
- Switching the Course Projects
- What Did We Change in Fall 2023
- The HyPer MVCC project
- Balancing the Difficulty
- Calcite on BusTub
- What’s next
Introduction
It has been a busy semester and also my last semester at CMU. Finally, I retired from the 15-445/645 teaching assistant position. Thanks to the whole TA team and Andy/Jignesh, the BusTub project evolved a lot and saw exciting changes in the past semester. In this blog post, I will go over all these changes and the outlook for the BusTub project.
This is a series of blog posts on the design choices and the design goals of the BusTub project during my time of being a TA for the Database Systems course. Previously, we had…
Switching the Course Projects
In the previous semesters, the course projects are composed of:
| Semester | Project 0 | Project 1 | Project 2 | Project 3 | Project 4 |
|---|---|---|---|---|---|
| Fall 2017 | / | Buffer Pool Manager | B+ Tree Index | Two-Phase Locking + Concurrent B+ Tree Index | Logging and Recovery |
| Fall 2018 | / | Buffer Pool Manager | B+ Tree Index | Two-Phase Locking + Deadlock Prevention/Detection | Logging and Recovery |
| Fall 2019 | / | Buffer Pool Manager | Hash Index | Query Execution | Logging and Recovery |
| Fall 2020 | / | Buffer Pool Manager | Hash Index | Query Execution | 2PL Concurrency Control + Deadlock Detection |
| Fall 2021 | / | Buffer Pool Manager | Hash Index | Query Execution | 2PL Concurrency Control + Deadlock Prevention |
| Fall 2022 | Trie | Buffer Pool Manager | B+ Tree Index | Query Execution + Optimization | Hierarchy 2PL Concurrency Control + Deadlock Detection |
| Spring 2023 | Copy-on-write Trie | Buffer Pool Manager | B+ Tree Index | Query Execution + Optimization, | Hierarchy 2PL Concurrency Control + Deadlock Detection |
| Fall 2023 | Copy-on-write Trie | Buffer Pool Manager | Hash Index | Query Execution + Optimization, | Multi-Version Concurrency Control |
Overall, the course staff tries rotating something every semester, and the structure of the course projects is kind of stabilized — students build the BusTub system bottom-up. They built a buffer pool manager as their first project to know how other parts of the system interact with the storage pool; then, some kind of index to know how to use the buffer pool; next, built some query executors over the storage things they have built in the previous two projects; finally, concurrency control.
As 80% of the course projects stay the same throughout the semesters, and people outside of CMU post solutions online, things are getting a little bit trickier here. Students read source code and walk-through articles from other students on the Internet without thinking of system programming problems on their own. Some of them start the course projects before the semester starts instead of on the intended dates, as most of the content stays the same.
Apart from the public solution and early start problems above, we also want to improve the quality of the course projects to help students learn more and achieve their learning goals. We want to balance the difficulty of the projects so that students can have a progressive and smooth experience during the semester. I redesigned the C++ Primer project to incorporate the C++ features that students will use throughout the semester so that students can learn these features early in the semester and have a solid foundation in C++ programming. The B+ tree project has been revamped several times by adding more guides and helper functions to ensure its difficulty fits well as the second project in the course. During this semester, we introduced a new MVCC project to better balance the difficulties.
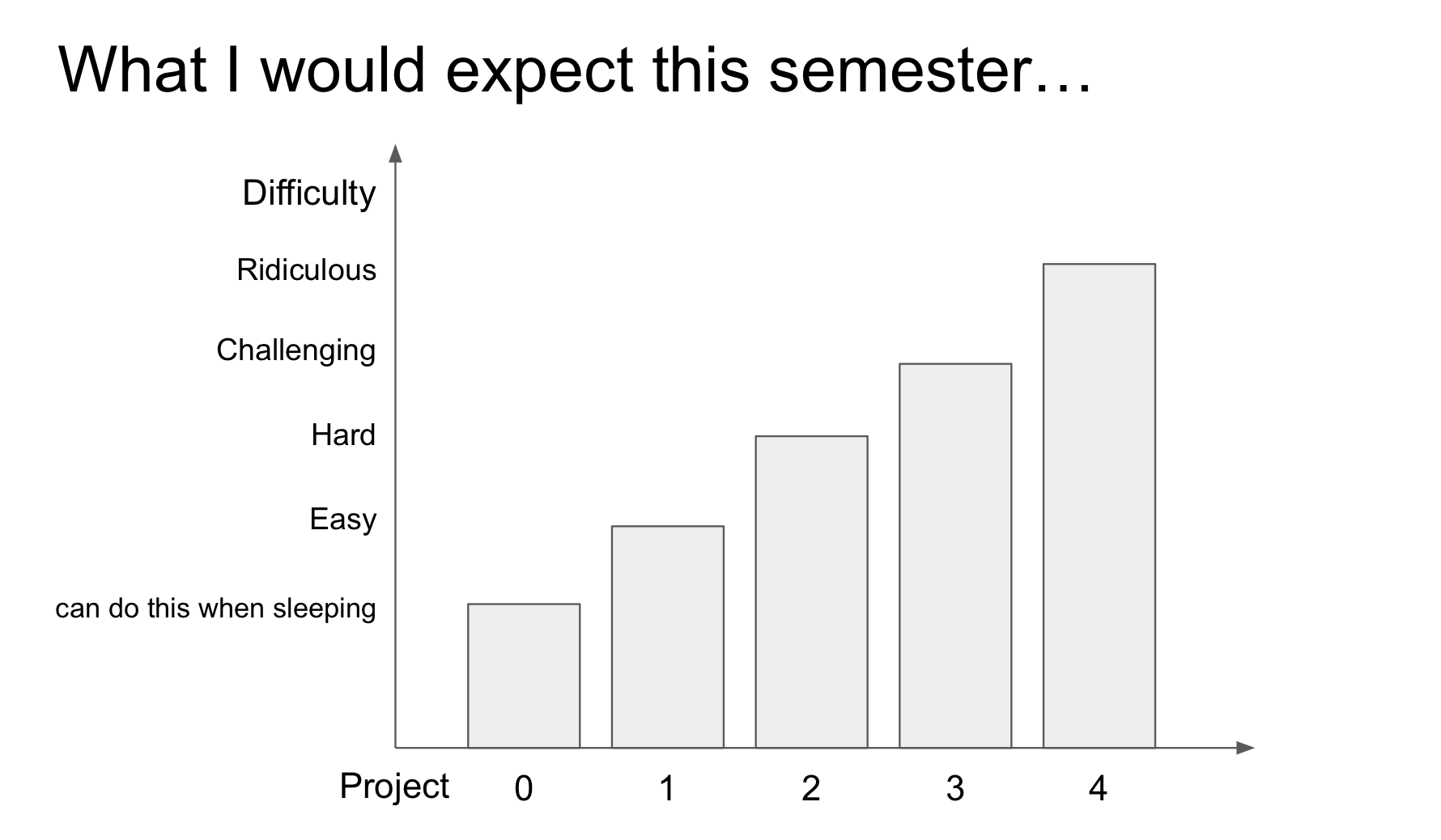
Besides the difficulty of the projects, we also want to ensure the functionalities students implement are correct by adding more test cases and improving the completeness of the test cases. Every semester when we revisit the test cases and the student feedbacks from previous semesters, we can always find bugs and design flaws in the reference solution, and we will fix them before releasing the projects.
In summary, we want students to get something out of the course, to think on their own and practice system programming, and to have a smooth learning experience. At the end of the semester, students should feel a sense of achievement that they built a database system, should learn the core ideas of a database system implementation, and improve their system programming skills. Therefore, we made some big changes to the course project composition this semester.
What Did We Change in Fall 2023
- In project 0, Abi introduced a C++ bootcamp composed of snippets of C++ code that use some C++ feature. We got far fewer students during office hours for Project 0 than in previous semesters.
- We added a disk scheduler in project 1 so that project 1 has a more reasonable amount of workload and students can implement I/O workers to exploit the parallelism of the disk.
- We switched from the B+ tree index to the hash index to lower the difficulty of the second project.
- We put more emphasis on query optimizations in project 3: point index lookup optimization, window functions, and group top N optimization.
- In project 4, students will need to implement the Hyper-style multi-version concurrency control. This project requires students to have a good understanding of everything they implemented before — it involves MVCC indexes (project 2) and new access method executors (project 3). It is also a super flexible project, as we only guided students through the algorithm they will need to implement without giving them any pseudo code and did behavioral tests (we will discuss this later in this blog post). I feel this project is truly challenging.
This creates a natural stair of difficulty throughout the semester — simply following and implementing the pseudo-code (project 1), reading the pseudo-code and debugging concurrency issues (project 2), reading the code of existing components in the system, and seeking ways to achieve a programming goal (project 3), and making design choices on students’ own based on what they implemented before (project 4).
The HyPer MVCC project
Deciding on the Base Implementation
One of the most significant changes this semester is the newly designed project 4 — multi-version concurrency control. This is super challenging and interesting to work on.
I have been thinking about redesigning the concurrency control project since the first semester I was there. At that time, we asked students to implement a lock manager, deadlock detection, and add 2PL in query executors in the concurrency control project (the 4th one). However, the implementation is kind of problematic when it comes to 2PL query executors. There are no concurrent test cases, and the reference solution itself does not seem correct. Implementing 2PL in a single-versioned database also does not seem to be common in industry database systems, as most products use more efficient MVCC implementations. In the spring semester, as Andy was not teaching the course (Charlie was doing that), he asked me not to change the projects too much to avoid creating troubles. Therefore, I worked on enhancing the test cases and better integrating the lock manager and the executors. At that time, I realized that MVCC was the only viable path if we wanted to integrate index with isolation levels into the system, and therefore, in the fall semester, I started refactoring the codebase and added MVCC support.
There are many MVCC implementation we can take from existing database systems. I compared these implementations and chose the HyPer way in the end. The HyPer implementation is simple and elegant. It stores the latest tuple in the main table, while the old version data are all in transaction local buffers. The serializable verification is based on the traditional backward OCC with precision locking optimization. As most things happen in memory, students do not need to interact with the buffer pool manager and can focus on the actual implementation of the algorithm. Reducing the contention on the disk also makes it possible for students to do performance optimizations and reason about concurrency issues.
HyPer is an in-memory database and BusTub needs to persist things to disk, and there is a later Umbra paper that ports the HyPer MVCC implementation to a disk-based database system. Both of the papers do not have the implementation detail down to the pseudo-code level, and I have to figure out a lot of things by myself. While the paper mainly explains how to construct the in-memory format for undo logs and do precision locking, many implementation details are left unknown: the procedure of insertions, deletions, and updates; what to store in the index; how to store the version chain in a disk-based system; etc. Therefore, I made several design choices in BusTub to adapt the algorithm to our educational system while simplifying the project. The below figure is the visualization of the BusTub system.
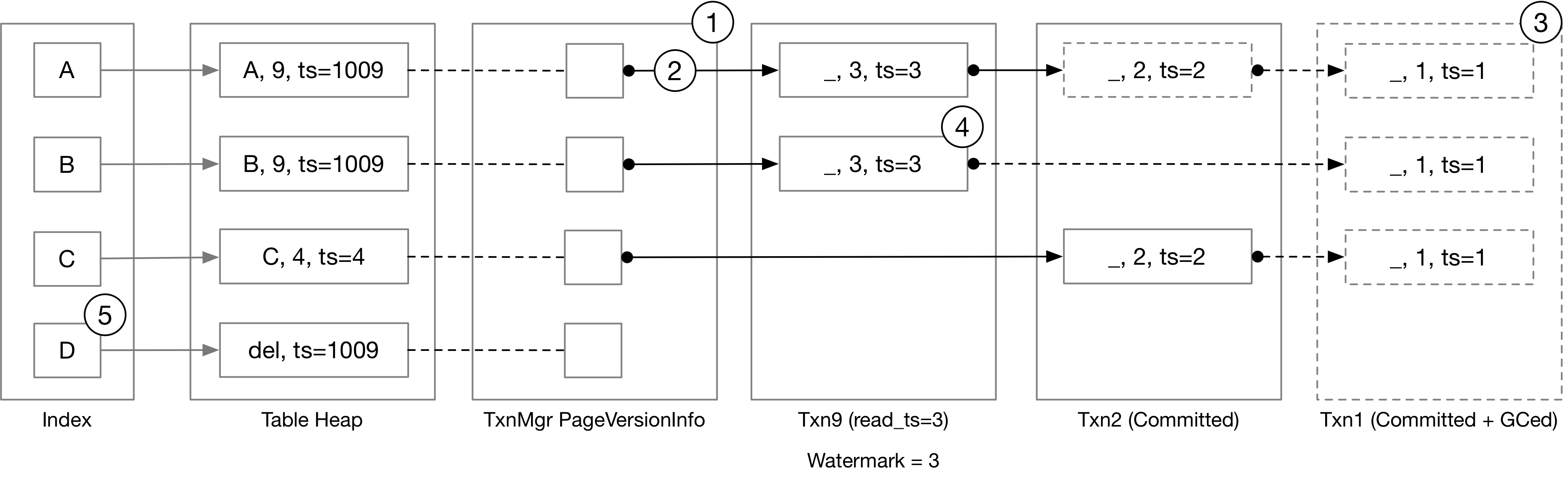
- In HyPer, there is a version vector that stores the pointer to the first undo log in the main table. In Umbra, the version vector is part of the buffer pool manager that is fetched along with the page. In BusTub, we store the link to the first undo log in the transaction manager. This turned out to be a bad design choice because we can never atomically insert the latest version into the version chain, and Avery will fix this in future semesters.
- The HyPer implementation uses a doubly-linked list so that it is easy to traverse back in the version chain and do garbage collection while running transactions. In BusTub, we use a singly-linked list in the version chain, to make it simpler to add things to the head of the chain.
- And because of the version chain linked list direction choice, we have to implement stop-the-world garbage collection instead of transaction-level garbage collection.
- We store exactly one undo log for a tuple in one transaction to avoid the complexity of having multiple undo logs of the same timestamp in the version chain when a transaction completes.
- We do not garbage-collect index and table heap, which means that the index always grows in size and unused slots in the table heap will never be reused. This also greatly simplifies the implementation.
- (Not shown in the figure) To simplify the serializable verification, we did not implement the precision locking algorithm. Instead, we simply have a write set and a read predicate set to do backward OCC verification.
Things worked well and I spent half of my fall break working on the reference solution for the new project. At the end of the fall break, we had everything ready — version chain, indexes, aborts, serialization verification. And I spent another week on the writeup, and yet another week on designing the test cases. I broke my own implementations twice and spent some hours to fix them.
Now It’s Meeting Time…
At the first meeting on this project, I presented the project as 10 tasks, where I expect each of them to take students 2-3 hours to complete. Abi was like, NOOOOO YOU CAN NOT ASK STUDENTS TO IMPLEMENT HYPER. Yuchen was like, okay…, I partially understand the algorithm. Avery was like, THIS IS SO CLEVER but I have a few more questions. Andy was kind of, well, it’s exciting to have MVCC in the course project, but we need to cut down the workload. Jignesh then followed, this is exciting and I really want to have that… but you need to think about the students — if everything is hard, it will be a disaster; but if we have three things that students will be challenged on, like version chain maintenance, garbage collection, and index insertion concurrency, it will be good. Anyway, the course stuff felt like the whole thing was too hard for students to implement.
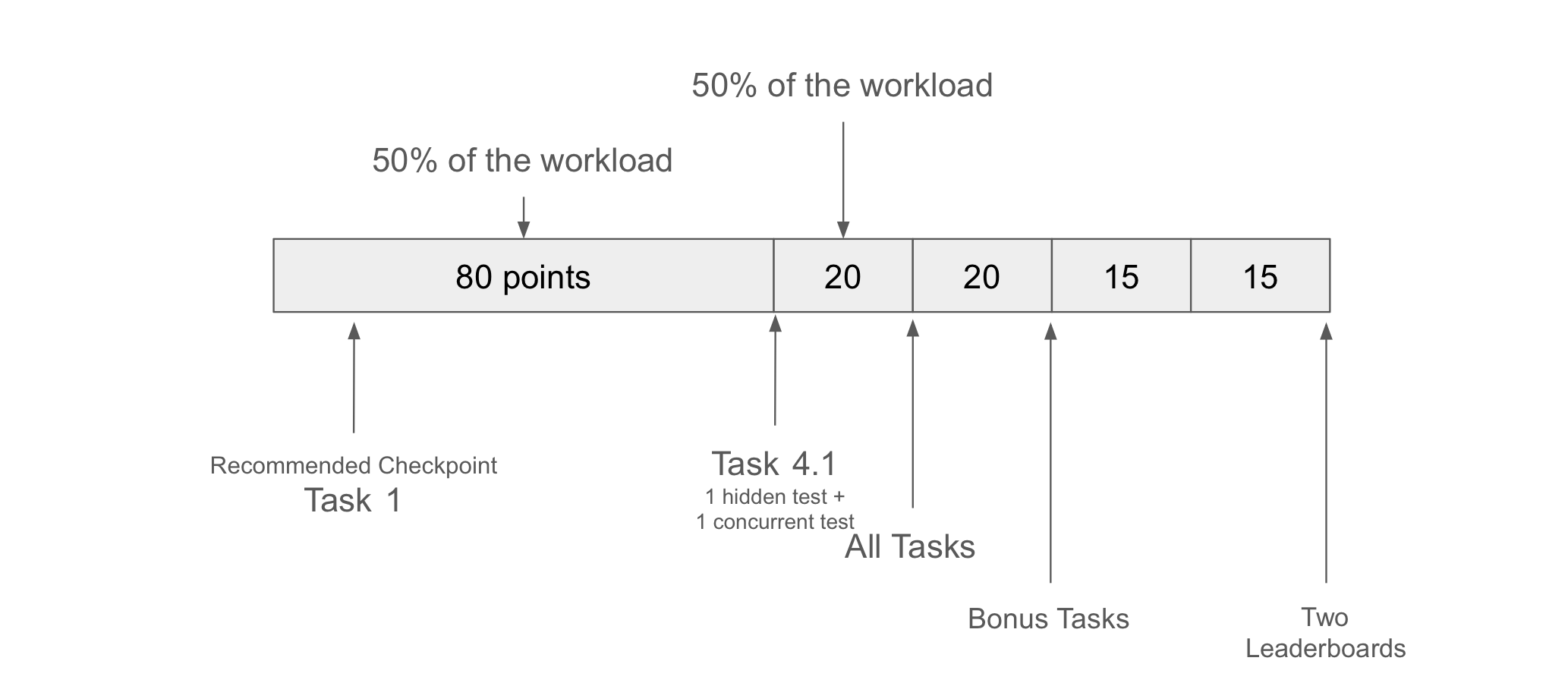
The other day after the DB lab meeting, I pitched Wan with the new MVCC project I was working on. As a former CMU undergrad who took 15-445 (well, I did not take the course because I TAed in my first semester), Wan provided a good estimation of what a normal student would be if they worked on the project. In the end, the course staff agreed on an easy 80 points on the MVCC implementation and a hard 20 points on concurrency and index stuff, with an extra 20 points bonus on aborts and serializable verifications. I assume getting 100 points would be as hard as the previous B+ tree project.
I also designed the project to have 2 leaderboard ranks: one for speed and the other for space utilization. Students can only get a full leaderboard bonus if their implementation is both fast and space-efficient. With multiple goals to optimize, and the goals are kind of mutually exclusive, students can learn the tradeoffs in designing a system.
Balancing the Difficulty
So, we have talked about how we designed the point distribution to make it easy to get the first 80 points and hard to get the other points. Indeed, in this project, I also employed multiple ways to balance out the difficulty in each part of the project.
I see the MVCC project as a system design problem: we give the specifications/interfaces in the write-up and do minimal checks on internal structures (mostly behavioral tests using SQL), and students will need to make design choices by themselves in a variety of aspects. The design goals in my mind:
- Understand existing code. Students will need to understand the structure of the current codebase and know the part of the code they can use to achieve a design goal.
- Understand design specifications. Students will need to read the write-up and understand how HyPer MVCC works.
- Implement the MVCC algorithm. Based on the code we have and the spec in the write-up, students will need to know how to leverage existing interfaces of the BusTub system to implement the spec.
- Design / Make design choices of some part of the MVCC algorithm. Specifically, students will need to think of the edge cases and come up with a correct order of doing operations for index modifications, aborts, and serializable verification.
- Debug and fix system code. We have some super hard concurrent behavioral SQL tests to ensure the system works correctly in a multi-threaded environment.
- Optimize for performance and efficiency. As part of the leaderboard tasks.
To achieve the design goals of the project, I applied a variety of strategies across different aspects of the project.
Write-up. We explained all the edge cases for insertion, deletion, and updates without indexes in the writeup. But for concurrent part and the indexes operations, we only provided a general approach to modify the version chain. This creates a natural stair in the difficulty of the project. Students who fully understand how to interpret the version chain can easily pass all single-thread tests. And they will need to think about the race conditions by themselves when implementing later parts. I used a lot of figures to illustrate how to perform an operation step-by-step. If someone ever worked with me in some companies, you will find the write-up of the MVCC project is basically a Chi-style design doc…
Refactors / Design Choices. It is easy to handle things when there is only one thread and when the test cases are simple. However, when MVCC indexes come along and when there are more concurrent tests, students will need to make design choices and do some refactors. For example, all DML executors (insert into an unused slot, delete, update without changing the primary key) all do the same thing — update a tuple. They could update a tuple to a deletion marker, or a new value. At this point, students should realize that they should extract the common part to a helper function. On the storage format, we only tested the minimal requirement (i.e., one undo log for one tuple in one transaction, replay the undo logs). There are a lot of things up to students to decide, for example, whether to store some data with the deletion marker. When it comes to the bonus tasks, students will likely need to do another refactor, because the sequential scan code will be reused across sequential scan, index scan, garbage collection, aborts, and serializable verification. Having one helper function for all of these things can help them better organize the code and fix bugs in one place.
Testing
- Hidden test cases vs public test cases. We make all concurrent test cases available to students so that they can debug them on their own. For single-thread test cases, we only made the test cases after the 80-point boundary hidden, which encourages students to design their test cases and think about the edge cases on their own in a later stage of the project.
- Concurrent tests vs single-threaded tests. We only had hard concurrent tests after the 80-point boundary. Single-threaded tests can detect logic problems in the implementation while concurrent tests can comprehensively test the system. A good combination of them can help students detect logic errors in the early stage so that they suffer less when debugging for concurrent things.
- Debug information. We asked students to implement a debug helper function to dump the version chain to stdout. I remember a student came to my office hours asking for garbage collection problems without implementing that helper function. I asked him to do that before I could help. After he dumped the table heap and version chain out, he immediately realized the timestamp written to the table heap was wrong.
- Large vs small test cases. Most of our test cases are fewer than 50 lines of SQL, so it is easier for students to understand what is going wrong in their systems.
- Behavioral test vs testing internal structure. We employed minimal checks on the internal structures of the version chain. We only had test cases that directly manipulated the table heap and the version chain in the first 30 points. All the rest of the test cases create transactions and use SQL queries to verify if the result received by the user is as expected. This helps students realize the connection between their MVCC structures and the end-user experience — when a user requests a SQL query with snapshot isolation, how the system satisfies the isolation level internally. I remember in the query executor project before I came to CMU, after students implemented the executors, the test cases simply set up the executors programmatically and verified the output. TAs (who took the course before) complained that they did not understand how SQL maps to these executors. After I added the SQL layer, they felt the connection between what they implemented and the SQL user interface and understood the full lifecycle of an SQL query. Understanding a system from the very top user interface to the bottom internal implementation can help students gain a full view of the system, which is an exciting learning experience.
Grading
- Point distribution. 80 easy points, 20 hard points, and 20 bonus points ensure students worry less about their grades and challenge themselves.
- Two Leaderboard Ranks. Students can learn about tradeoffs in a real system when they optimize for two seemingly mutually exclusive goals. With a vanilla implementation, students who have a larger throughput will have more garbage in their system, and vice-versa. However, doing garbage collection too frequently will also affect the system’s performance. A good implementation should balance these two goals.
With my methodology of balancing the difficulty of the project, the outcome of the grades is as expected. About 10 students finished all tasks including bonus ones, and 20% of the students got 100 points. About 50% of the students tried reaching 100 points but failed, while nearly all students got 80 points in this project.
Calcite on BusTub
As part of my optimizer research with Andy, I studied implementations of some optimizer frameworks. Apache Calcite is the one I have a special interest in, and I tried implementing something over that.
I plugged Calcite into the query frontend of BusTub. BusTub starts with an HTTP service, listening for JSON query plans and serving the catalog. Calcite parses the SQL, generates the query plan on BusTub, and sends it to the BusTub HTTP service.
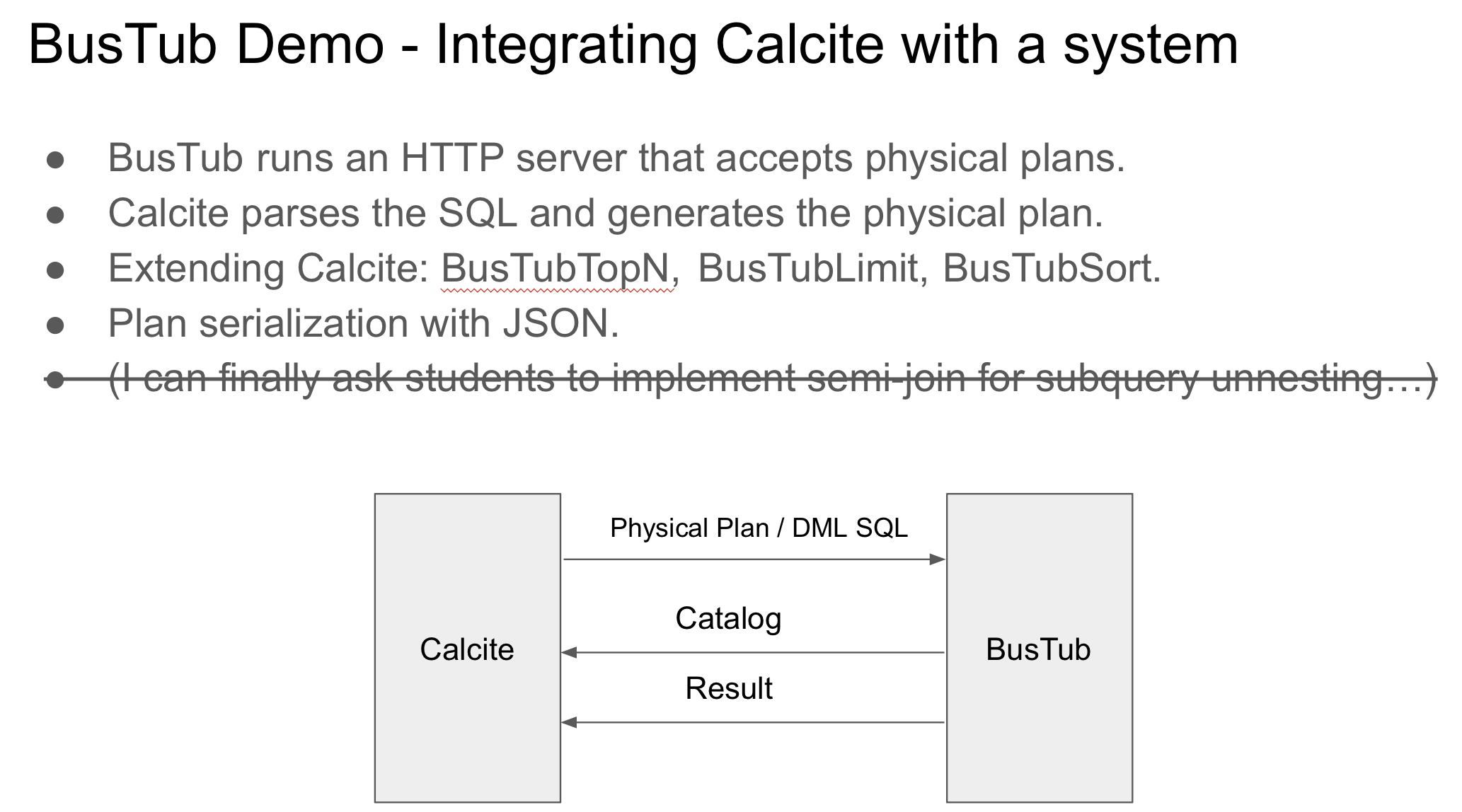
The Calcite frontend opens up a lot of opportunities for BusTub — for example, students can implement semi join executors. With that, Calcite can unnest correlated subqueries and execute them on BusTub. We could have a semester focusing on execution (implementing a lot of different query executors) if we use Calcite as the frontend, and alternatively, a semester focusing on optimization (implementing a lot of rules in BusTub).
What’s next
- Recovery. This is a missing part of BusTub and probably we can have a short recovery project as the extra last project in future semesters. The catalog should be persisted, and transition operations should be written to a redo log.
- LSM index. Most database systems using the LSM index usually store all the data in the LSM tree instead of having a table heap. If we have the LSM index as Project 2, we will also have Project 3 to support the LSM index in access method executors with primary keys and project 4 to implement MVCC over the LSM index (i.e., adding timestamp into the LSM key). LSM indexes also make it easier to support variable-size data as we do not update key-value pairs in place, which opens a lot of possibilities for the BusTub project.
- Alternating between optimization and execution with the Calcite frontend.
By the way, my personal rank of my favorite BusTub course projects…
- Top 1: Multi-Version Concurrency Control
- Top 2: Query Execution + Optimization
- Top 3: B+ Tree Index
Being part of an educational database project is a fascinating experience for me. Instead of doing fancy optimizations over the system, we consider more about readability of the system. We want to get new features into the system without creating learning barriers. We redesign things from the industry and the academia in the simplest way, so that students can understand the core ideas very quickly and have hands-on experience with those new technologies. We also want to create opportunities for students pursuing advanced studies in database systems to try whatever they want in the system by making the design flexible, and therefore they can do whatever they want to optimize their implementation. The different design goals of an educational system and other industry systems, as well as communication with students, have shaped me to be a better engineer who can explain complex things in a simple way so that people can understand my work and I can deliver hard features into a system.
Well, this is my last semester at CMU and I finally retired from being a teaching assistant in the database system course. An exciting journey as a full-time system software engineer awaits ahead, and I am looking forward to my full time job at Neon.
Thanks for reading and feel free to leave your comments at GitHub.