State Store in Streaming Systems
Table of Contents
- Introduction
- Full State — Operators maintain their complete state
- Shared State — Sharing state among operators
- Partial State — Operators store only partial information
- Reference
Introduction
Data processed by a stream processing system is often unbounded: data keeps flowing in from the data source, and users need to see the real-time results of SQL queries. At the same time, the compute nodes in the stream processing system may encounter errors or failures, and they may need to scale up or down in real-time based on user demands. In this process, the system needs to efficiently transfer the intermediate states of computations between nodes and persist them in external systems to ensure uninterrupted computation.
This blog post introduces three approaches to storing the state of stream processing systems in the industry and academia: storing complete state (e.g., Flink), storing shared state (i.e., Materialize / Differential Dataflow), and storing partial state (e.g., Noria (OSDI ‘18)). Each of these state storage solutions has its advantages and can provide some insights for the development of future stream processing engines.
Assuming there are two tables in a shopping system:
visit(product, user, length)represents the number of seconds a user views a product.info(product, category)represents the category to which a product belongs.
Now we want to query: What is the longest time that a user has viewed a product in a certain category?
CREATE VIEW result AS
SELECT category,
MAX(length) as max_length FROM
info INNER JOIN visit ON product
GROUP BY categoryThis query includes a join operation between two tables and an aggregation operation. The following discussion will be based on this query.
Assuming the current state of the system is:
info(product, category)
Apple, Fruit
Banana, Fruit
Carrot, Vegetable
Potato, Vegetable
visit(product, user, length)
Apple, Alice, 10
Apple, Bob, 20
Carrot, Bob, 50
Banana, Alice, 40
Potato, Eve, 60Under this scenario, the query result should be:
category, max_length
Fruit, 40
Vegetable, 60The Fruit category was viewed by users for a maximum of 40 seconds (corresponding to Alice’s visit to Banana); the Vegetable category was viewed for a maximum of 60 seconds (corresponding to Eve’s visit to Potato).
In common database products, the system usually generates the following execution plan for this query (not considering the optimizer):
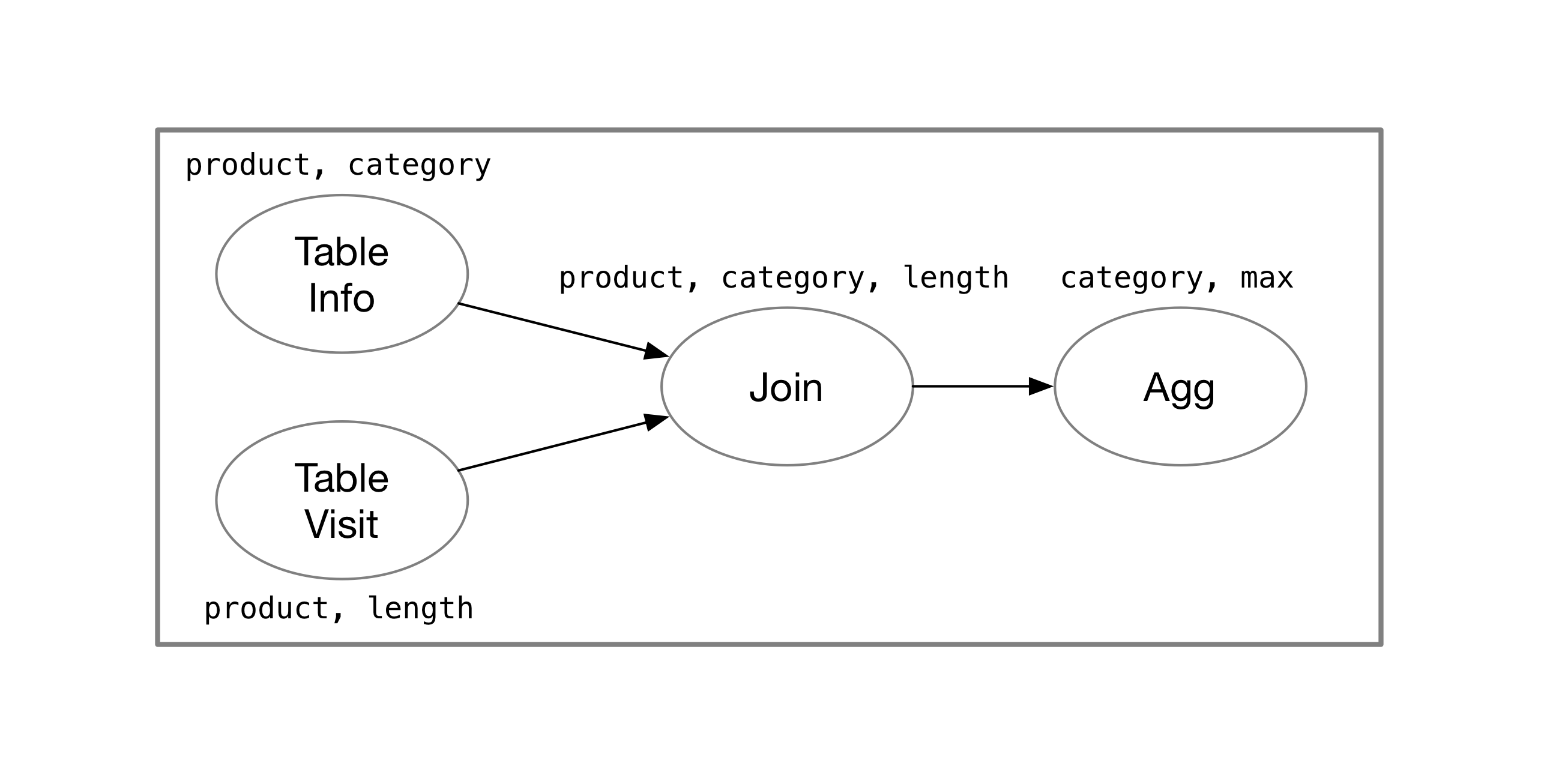
The execution plan of a stream processing system is not significantly different from the plans of common database systems. Below, we will explain how various stream processing systems represent and store the intermediate states of computations.
Full State — Operators maintain their complete state
Stream processing systems such as Flink persist the complete state of each operator and also propagate data update information among operators in the stream computation graph. This method of storing state is very intuitive. The SQL query described earlier would create this computation graph in systems like Flink:
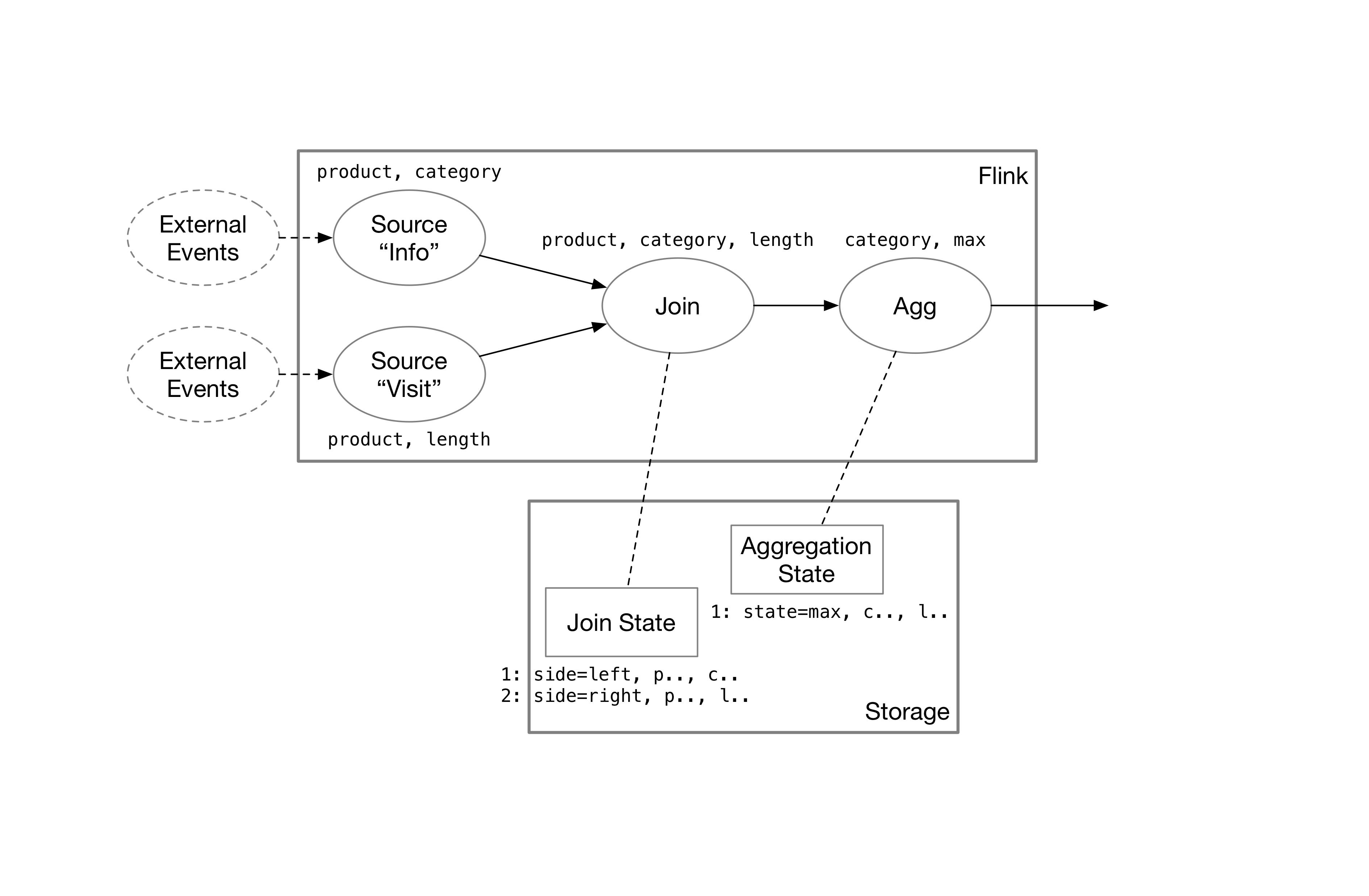
The data source emits messages indicating the addition or removal of rows. After going through the stream operators, these messages are transformed into the desired results.
State Storage of Join State
When messages from the data source enter the system, the first operator they encounter is the join operator. Let’s revisit the Join condition in the SQL query: info INNER JOIN visit ON product. After receiving messages from the left side info, the join operator first fetches the rows from the right side visit that have the same product, and then sends them downstream. Subsequently, the messages from the left side info are recorded in its own state. The processing of messages from the right side follows the same pattern.
For example, let’s say the right side visit receives a message stating that Eve looked at Potato for 60 seconds (+ Potato Eve 60). Assuming the left side info already has four records in its state, the join operator would query the records where product = Potato from the left side info and obtain the result that Potato is a Vegetable. It would then send Potato, Vegetable, 60 downstream.
Furthermore, the state of the right side visit would include a record Potato -> Eve, 60 as well. As a result, if there are any changes in the left side info, the join operator can also send the corresponding updates to the downstream visit operator.
State Storage of Aggregation State
The messages are then passed to the aggregation operator, which needs to group the data based on the category and calculate the maximum length for each category.
Some simple aggregation states (such as sum) only need to keep track of the current value for each group. If an insert message is received from the upstream operator, the sum is incremented by the corresponding value. If a delete message is received, the sum is decremented. Therefore, the state required for aggregations like sum and count (without distinct) is very small.
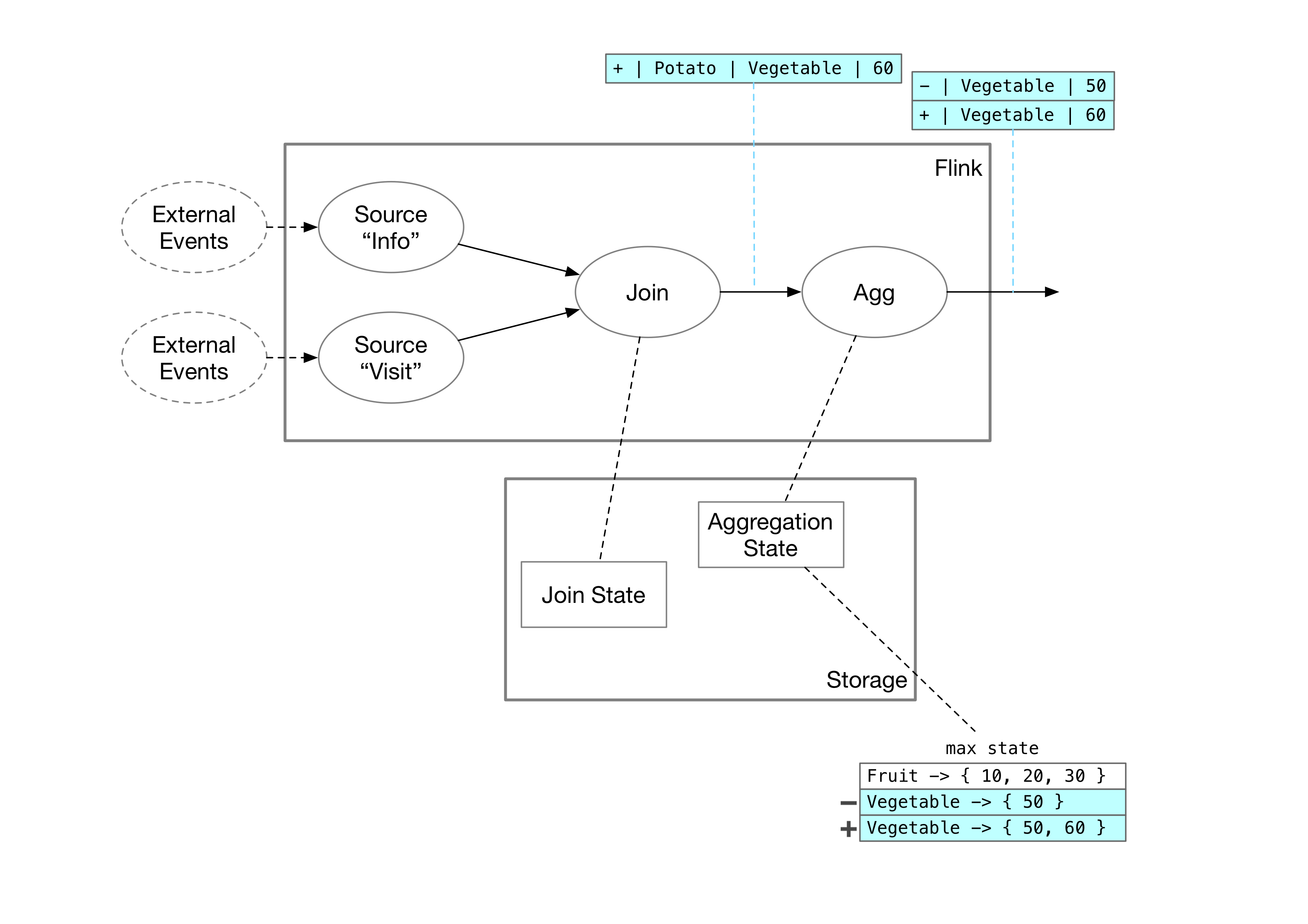
However, for the max state, we cannot just record the maximum value. If a delete message is received from upstream, the max state needs to send the second largest value as the new maximum value to the downstream. If only the maximum value is recorded, we would not be able to determine the second largest value after removing the maximum value. Therefore, the aggregation operator needs to store the complete data for each group. In our example, the AggMaxState currently stores the following data:
Fruit -> { 10, 20, 30, 40 }
Vegetable -> { 50 }If an insert message Potato, Vegetable, 60 is received from the upstream join operator, the aggregation operator would update its state:
Fruit -> { 10, 20, 30, 40 }
Vegetable -> { 50, [60] }It would also send the update for the Vegetable group downstream:
DELETE Vegetable, 50
INSERT Vegetable, 60The entire process is illustrated in the following diagram:
Summary
Stream processing systems that store complete state typically have the following characteristics:
- Messages indicating data changes (addition/deletion) are propagated unidirectionally in the stream computation graph.
- Stream operators maintain and access their own state. In the case of multi-way Joins, the stored state may be duplicated. This will be explained in more detail when discussing shared state later in this blog post.
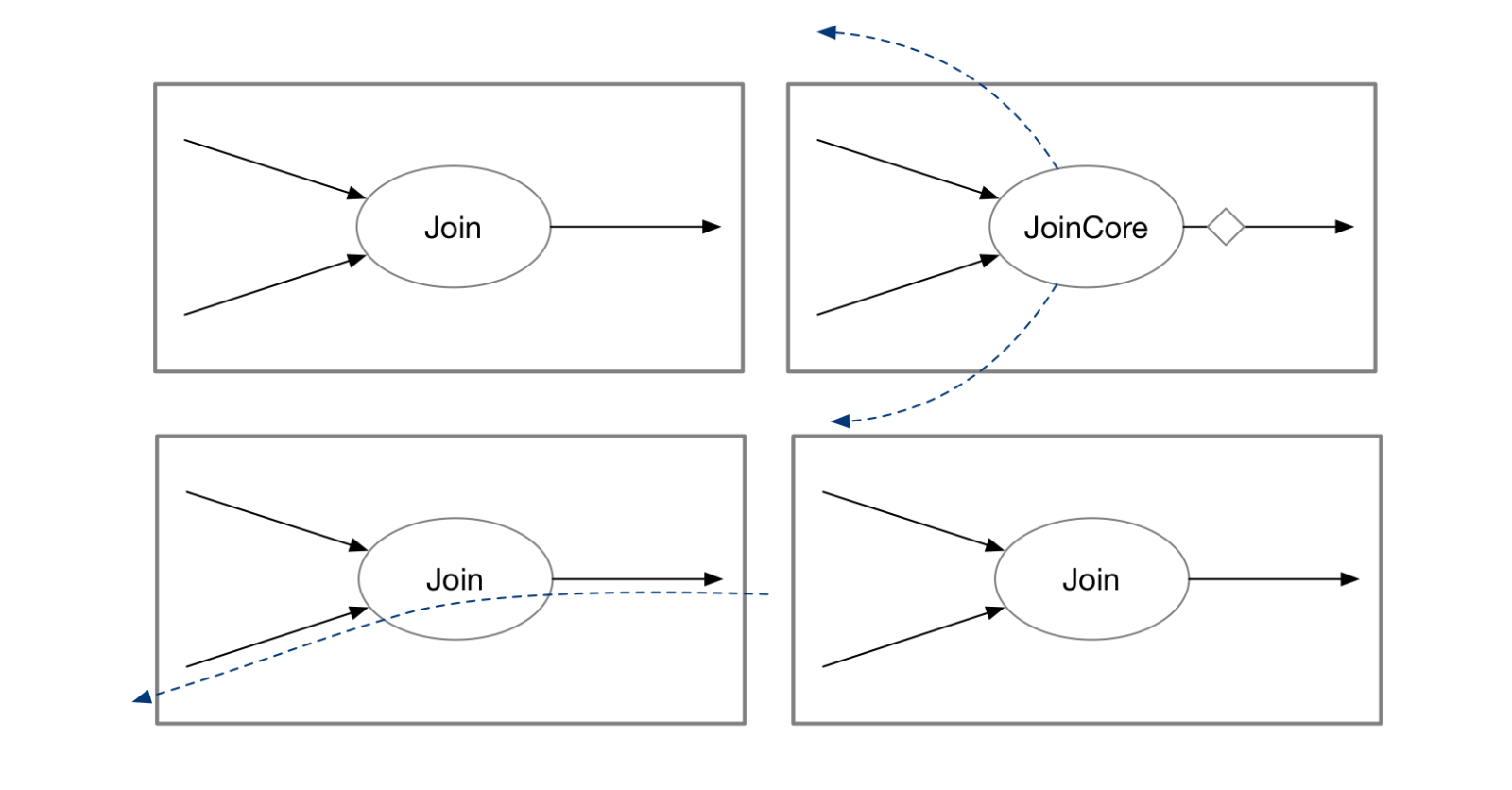
Shared State — Sharing state among operators
We will use the example of Shared Arrangement in Differential Dataflow (the computation engine underneath Materialize) to explain the implementation of shared state. Differential Dataflow will be used as an abbreviation for Differential Dataflow.
Arrange Operators and Arrangements in Differential Dataflow
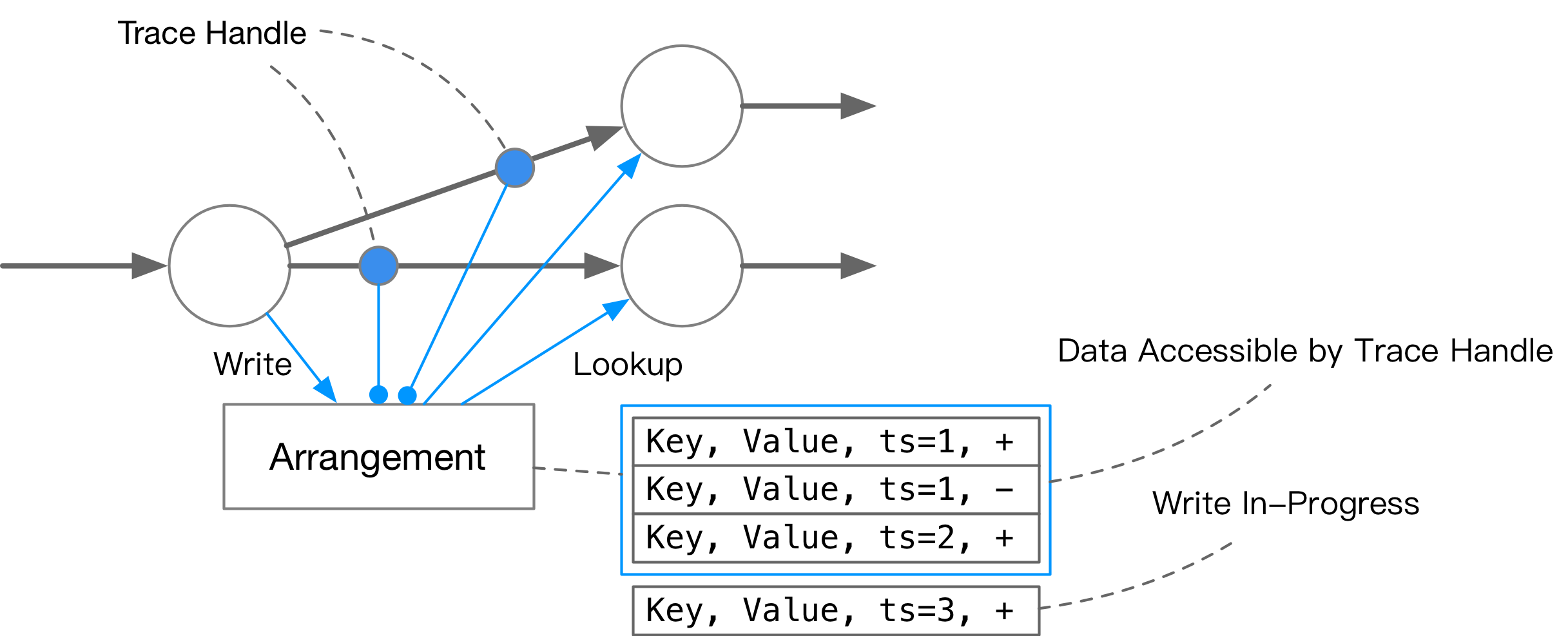
Differential Dataflow uses arrangements to maintain state. In simple terms, Arrangement is a key-value map data structure that supports MVCC. It stores the mapping of key to (value, time, diff). With Arrangement, you can:
- Query the mapping relationship of key-value at a certain point in time using a handler.
- Query the changes of a key during a certain period of time.
- Specify the watermark for the query and merge or delete historical data that is no longer used in the background.
In Differential Dataflow, most operators do not have states, and all states are stored in arrangements. arrangements can be generated using arrange operators or maintained by operators themselves (such as the reduce operator). In the computation graph of Differential Dataflow, there are two types of message passing:
- Changes in data at a certain moment in time
(data, time, diff). This type of data flow is called Collection. - Snapshots of data, which are handlers of arrangements. This type of data flow is called Arranged.
Each operator in Differential Dataflow has certain requirements for its input and output, as shown in the following examples:
- Map operator (corresponding to SQL’s Projection) takes Collection as input and outputs Collection.
- JoinCore operator (a stage of Join) takes Arranged as input and outputs Collection.
- ReduceCore operator (a stage of Aggregation) takes Arranged as input and outputs Arranged.
Later on, we will provide a detailed introduction to the JoinCore and ReduceCore operators in Differential Dataflow.
From Differential Dataflow to Materialize
Materialize converts SQL queries input by users into the computation graph of Differential Dataflow. It is worth mentioning that SQL operations such as join and group by often do not correspond to a single operator in Differential Dataflow. By following the flow of messages, let’s see how Materialize stores states.
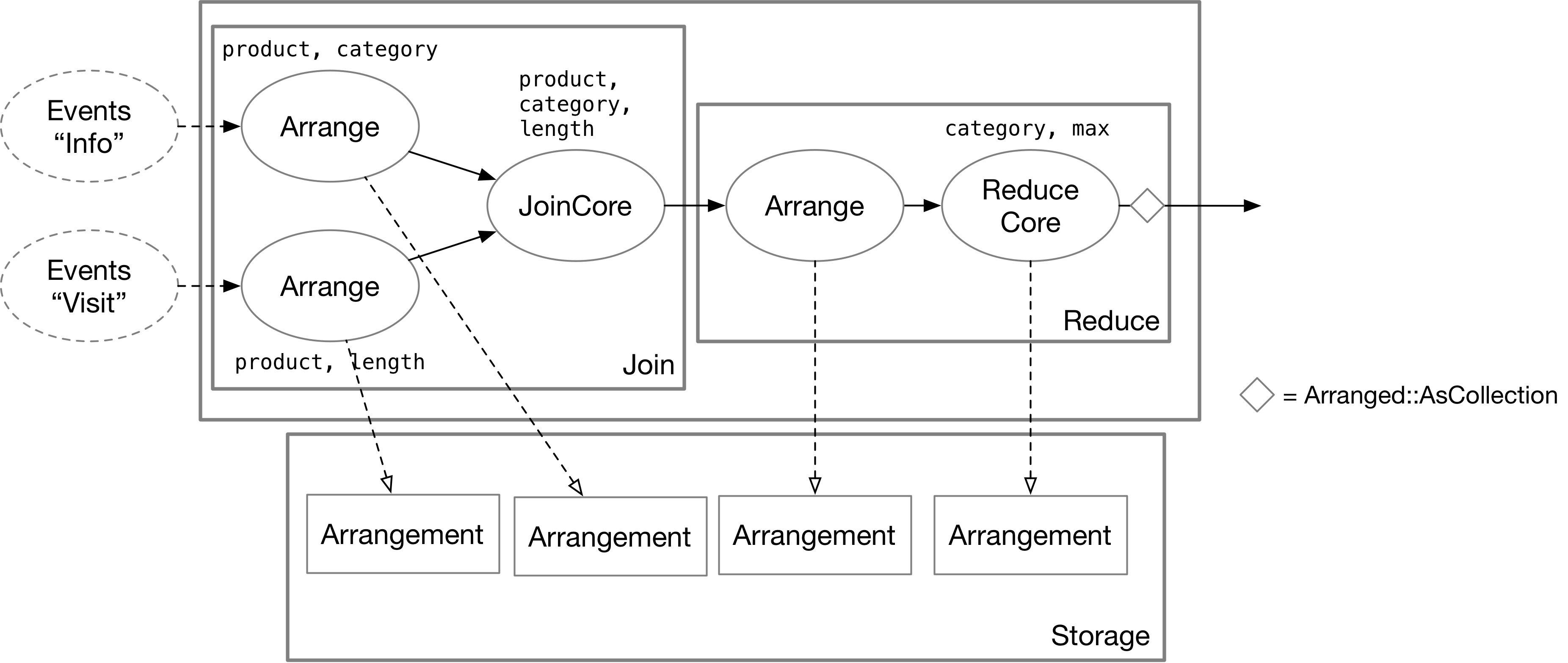
State Storage of Join State
The A Join B operation in SQL corresponds to three operators in Differential Dataflow: two Arranges and one JoinCore. The arrange operators persist the states of the two sources separately based on the join keys, storing them in arrangements in the form of key-value pairs. After batching the inputs, the arrange operators send TraceHandles to the downstream JoinCore operator. The actual join logic takes place in the JoinCore operator, which does not store any states.
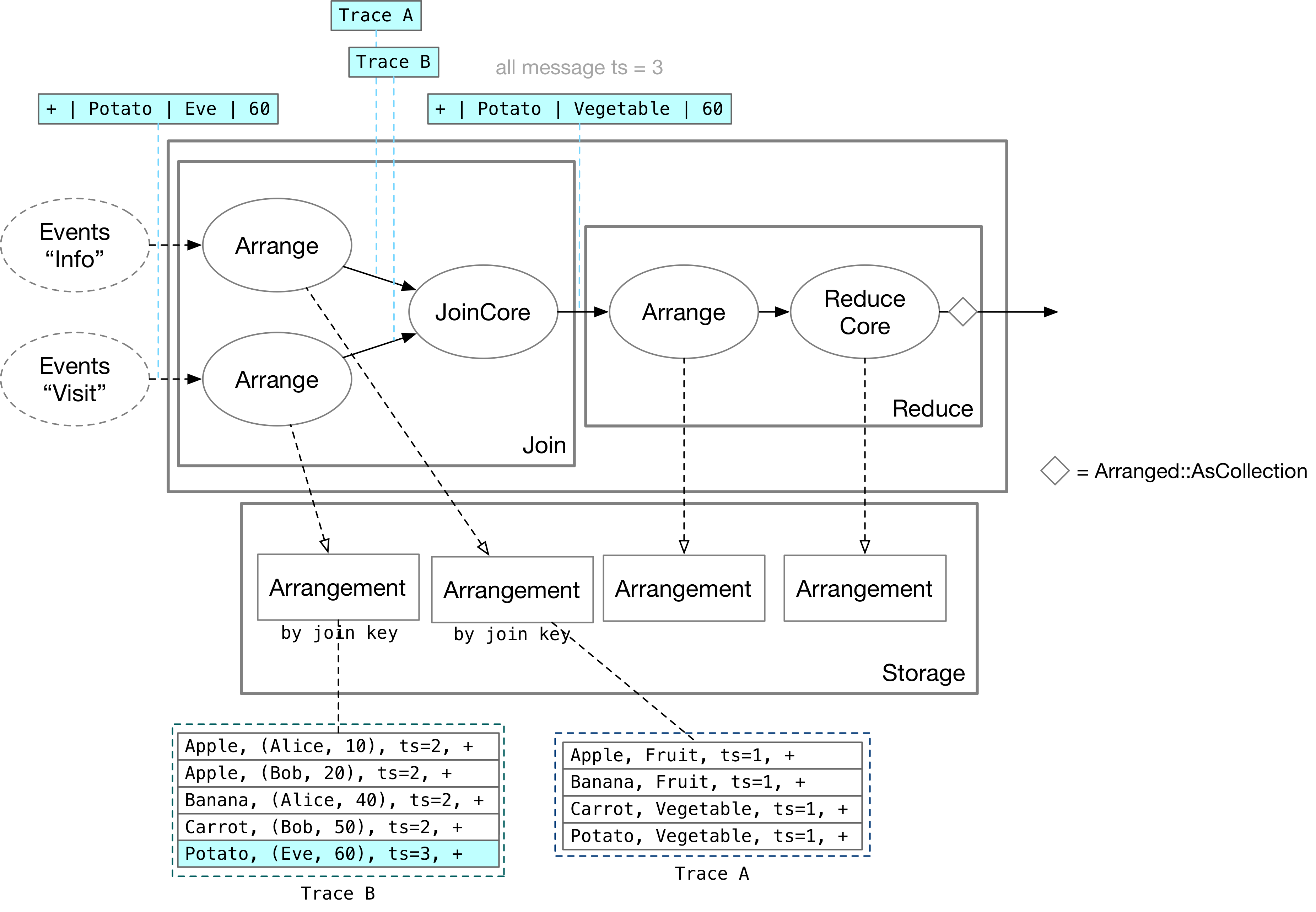
As shown in the above figure, suppose a new update comes to the Visit side: Eve looks at the Potato for 60 seconds. The JoinCore operator accesses this update through Trace B and queries the rows with product = Potato on the other side (Trace A). It matches that Potato is a vegetable and outputs the change Potato, Vegetable, 60 downstream.
State Storage of Reduce (Aggregation) State
In Differential Dataflow, SQL aggregation operator corresponds to the reduce operation. The reduce operation includes two operators: Arrange and ReduceCore. The arrange operator stores the input data based on the group key, and the ReduceCore operator maintains an Arrangement to store the aggregated results. Finally, the results are output as a collection using the as_collection operation.
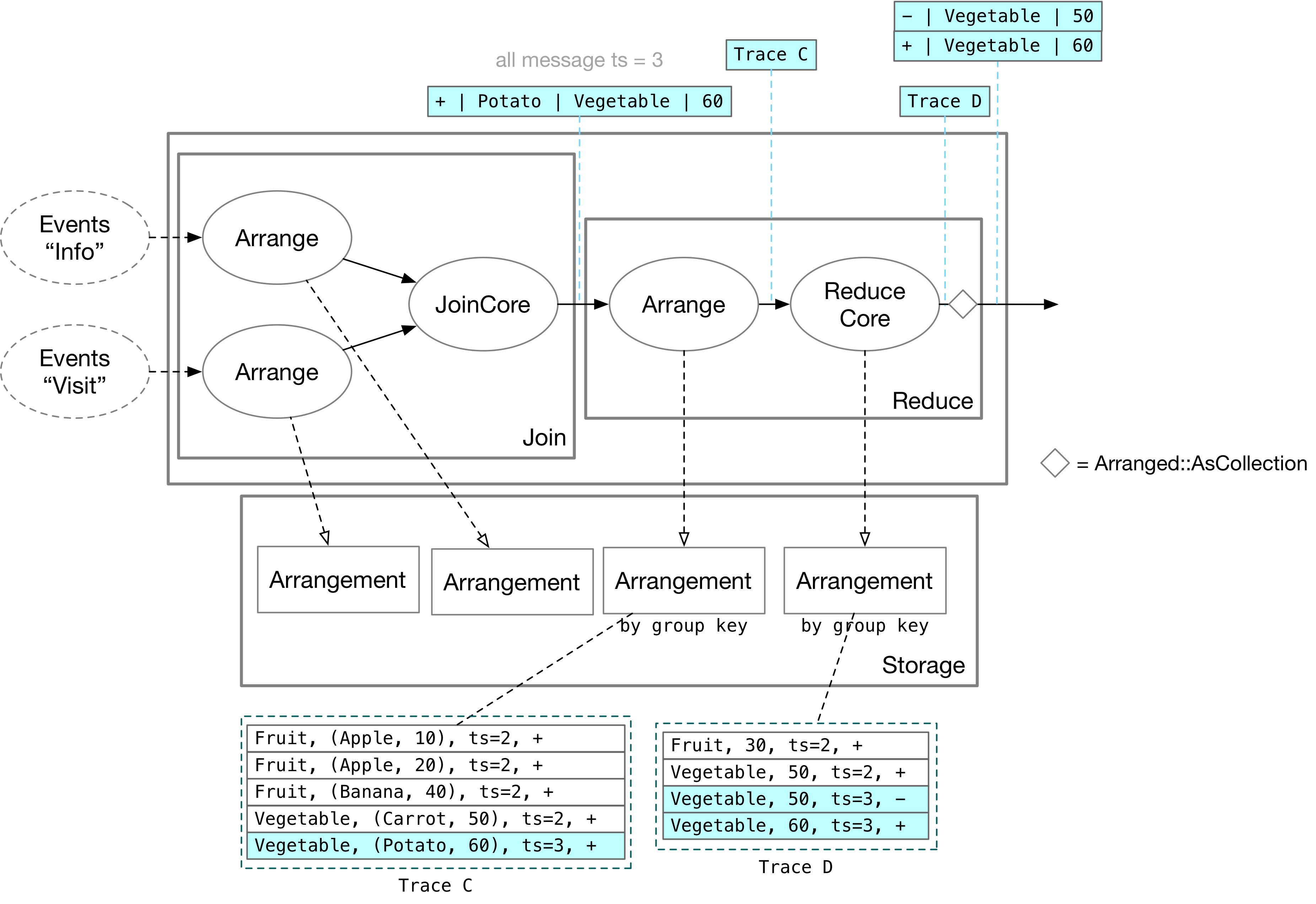
When the update from the Join operation arrives at the reduce operator, it is first stored in Arrangement by the arrange operator based on the group key. After receiving Trace C, the ReduceCore operator scans all the rows with key = Vegetable and calculates the maximum value. The maximum value is then updated in its own Arrangement. After passing through the as_collection operation, Trace D can be output as data updates, which can be processed by other operators.
Convenient State Reuse for Operators
Since the operators that store states in Differential Dataflow are separate from the operators for actual computation, we can take advantage of this property to reuse operator states.
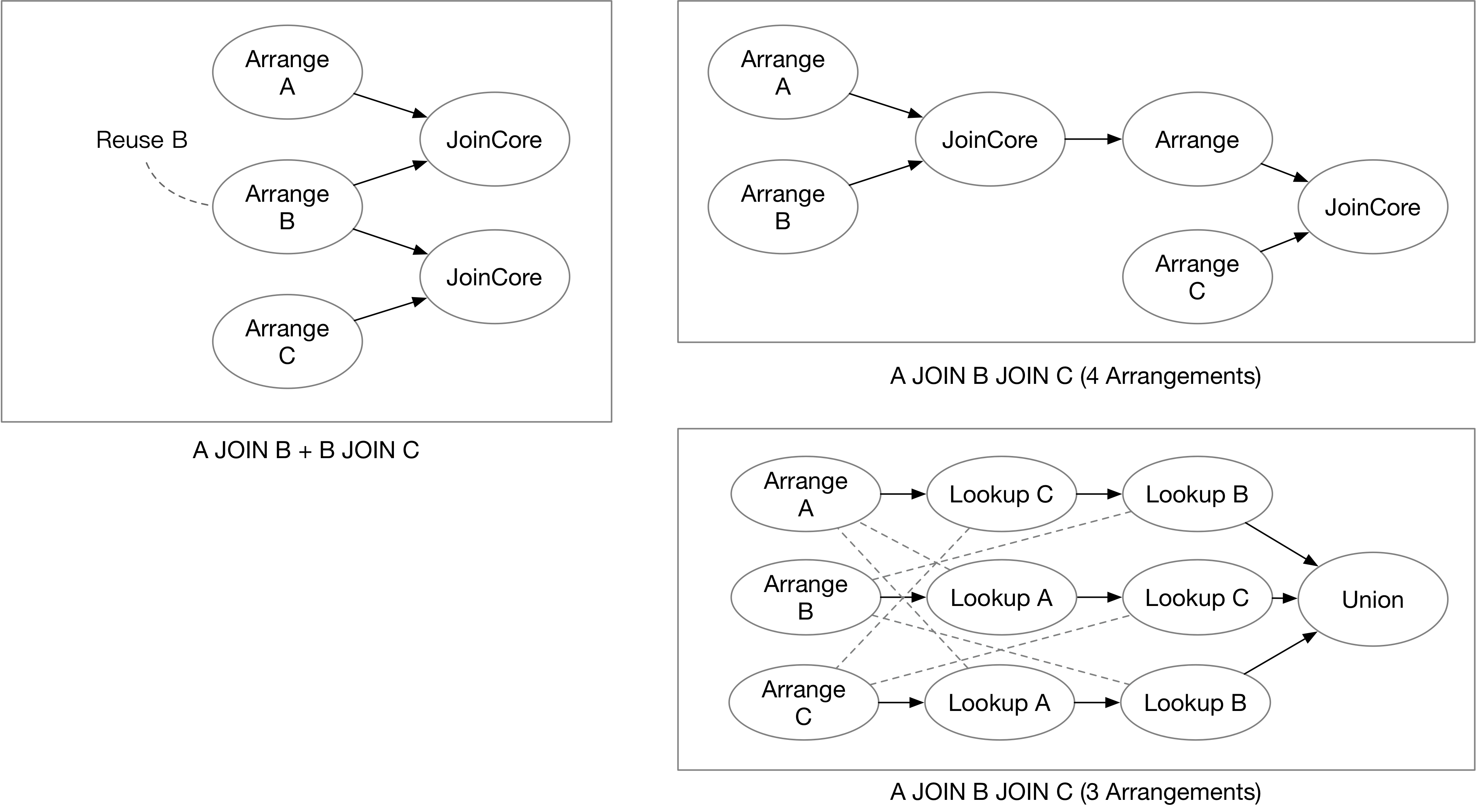
For example, if a user wants to query A JOIN B and B JOIN C at the same time, in Differential Dataflow, a possible computation graph would generate three arrange operators and two JoinCore operators. Compared to stream processing systems that store complete states, we can avoid duplicating the state of B.
Another example is a multi-way join, such as SELECT * FROM A, B, C WHERE A.x = B.x and A.x = C.x. In this example, if JoinCore operator is used to generate the computation graph, there is still a possibility of state duplication, requiring a total of four arrangements.
Besides being converted into the JoinCore operator in Differential Dataflow as described above, Materialize’s SQL Join can also be converted into Delta Join. As shown in the figure, we only need to generate three arrangements for A, B, and C respectively, and then use the lookup operator to query the rows in A that correspond to modifications in B and C (and vice versa). Finally, we perform a union to obtain the result of the join. Delta Join can make full use of existing arrangements for calculation, greatly reducing the number of states required for Join.
Overheads of Shuffling States
In a streaming system, it is often impossible to store and compute all the data generated during computation on a single node. Therefore, the execution generally needs to be partitioned by some keys so that it can be distributed on multiple compute nodes. In the example of a two-table join shown below, the arrangements of two tables A and B may be generated on nodes different from the nodes performing the join operations. The join operation might be using a different arrange key or using different number of nodes (parallelism).
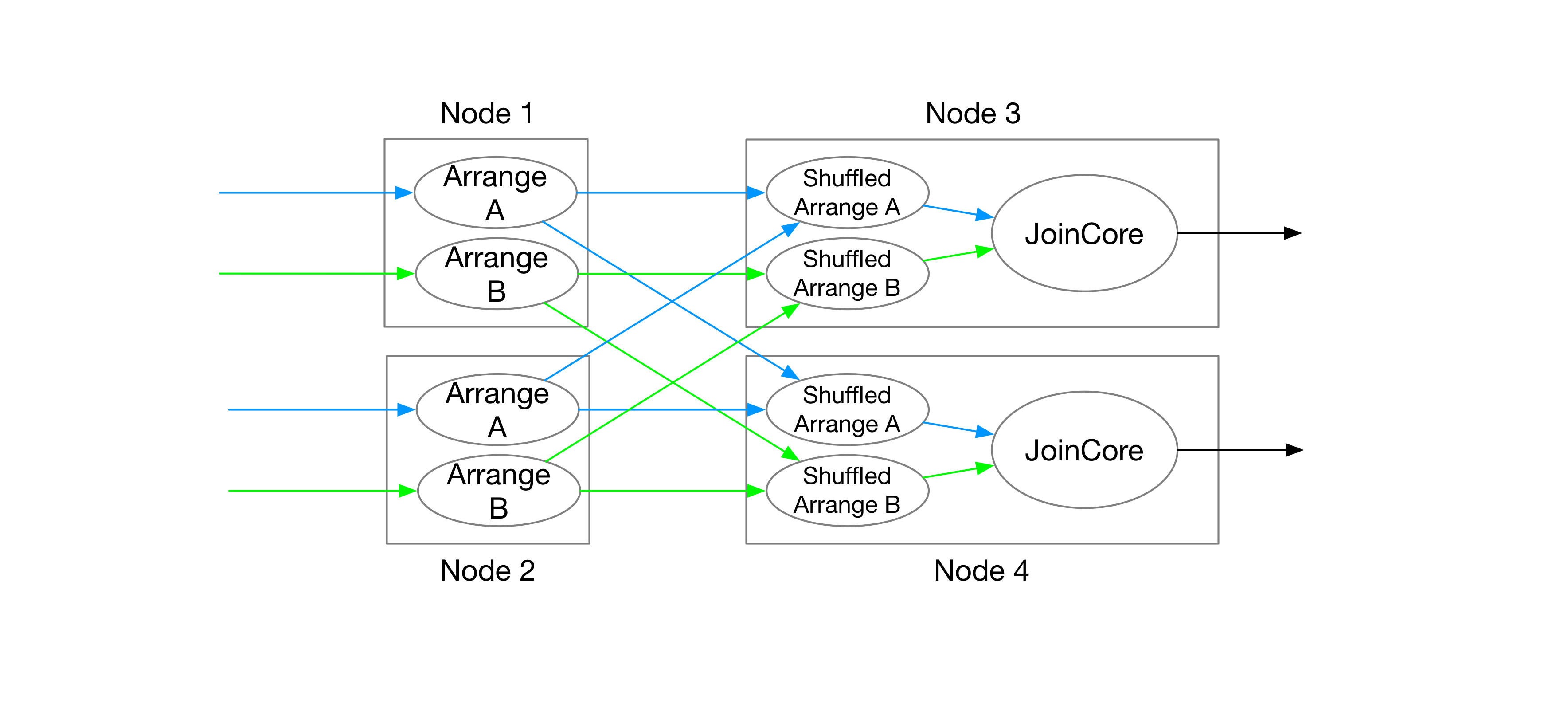
In this case, shuffles on arrangements are inevitable in Differential Dataflow. We will need to store the fraction of keys required by a partition of joins on the compute node performing the join by creating new arrangements. Generally, arranging and computing on different nodes will greatly increase the computation delay, and arranging and computing on a single node cannot fully utilize the resources of distributed systems, which is a contradictory situation.
As long as the system ensure that the distribution of keys and the parallelism are the same for the arrangements and joins, states can still be shared without being shuffled.
There was a mistake in this blog post explaining Differential Dataflow to use remote access for partitioned states, as pointed out in GitHub Discussion. We have fixed it.
Summary
In a shared state streaming system, the computation logic and storage logic of operators are divided into multiple operators. Therefore, different computation tasks can share the same storage and reduce the number of stored states. If you want to implement a shared state streaming system, it generally has the following characteristics:
- The streaming computation graph not only carries the data changes but also includes the shared information of states (such as Differential Dataflow’s Trace Handle).
- Accessing state in streaming operators incurs certain overheads, but compared to streaming systems that store complete states, the number of stored states is smaller throughout the streaming computation process, thanks to state reuse.
Partial State — Operators store only partial information
In the Noria system introduced in Noria (OSDI ‘18), computations are not triggered when data sources are updated, and streaming operators do not store complete information.
For example, when a user creates a view (CREATE VIEW result), the system builds the dataflow but not compute anything. When a user executes the following query on a previously created view:
SELECT * FROM result WHERE category = "Vegetable"The system then starts piping data on the dataflow. During the computation, only the data related to category = "Vegetable" is processed and the relevant state is stored. Using this query as an example, we will explain Noria’s computation method and state storage.
Upqueries
Each operator in Noria only stores a portion of the data. A user’s query may directly hit the cached portion of the state or may need to backtrack to upstream queries. Assuming that all operators’ states are empty at the moment, Noria needs to recursively query the state of upstream operators through upqueries to obtain the correct result.
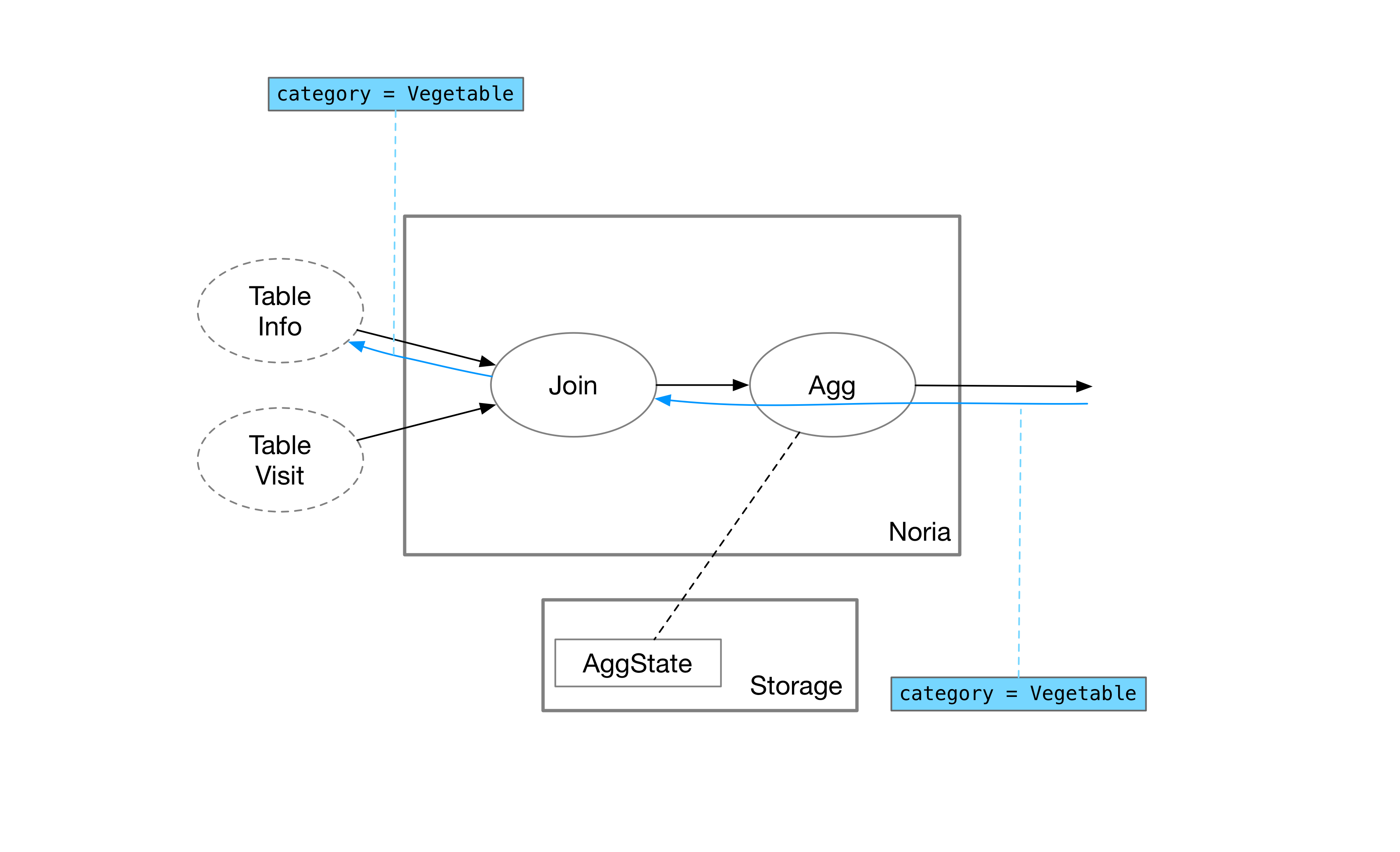
The user queries for the maximum value of category = "Vegetable". In order to compute this result, the aggregation operator needs to know all records with the category of vegetables. Therefore, the aggregation operator forwards this upquery to the upstream join operator.
The join operator needs to obtain all information related to vegetables by querying two upstream tables separately. Since the category belongs to the Info table, the join operator forwards this upquery to the Info table.
Join Operator Implementation
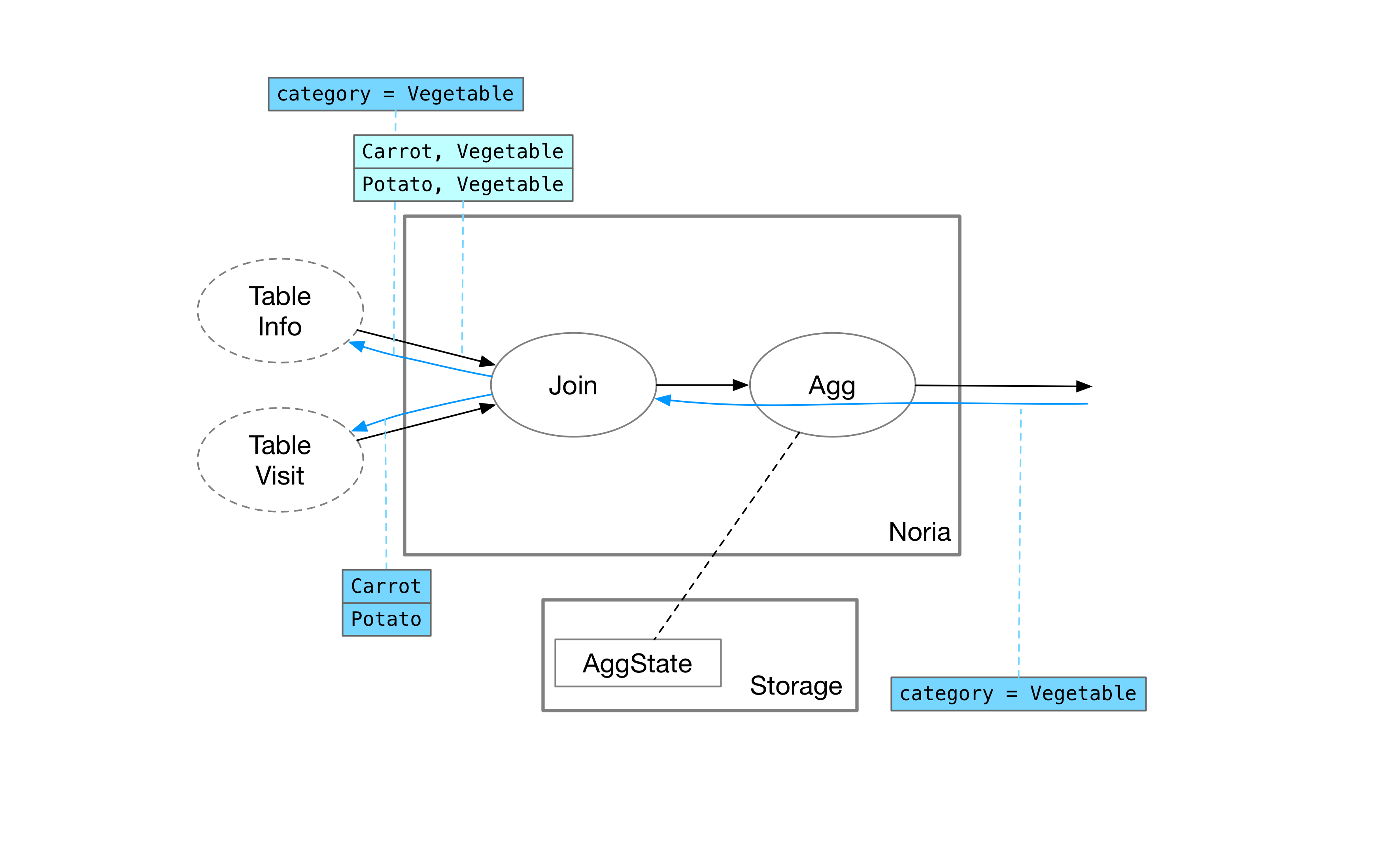
After the Info table returns all products under the vegetable category, the join operator sends an upquery to the other side, the Visit table, to query the browsing records corresponding to carrots and potatoes.
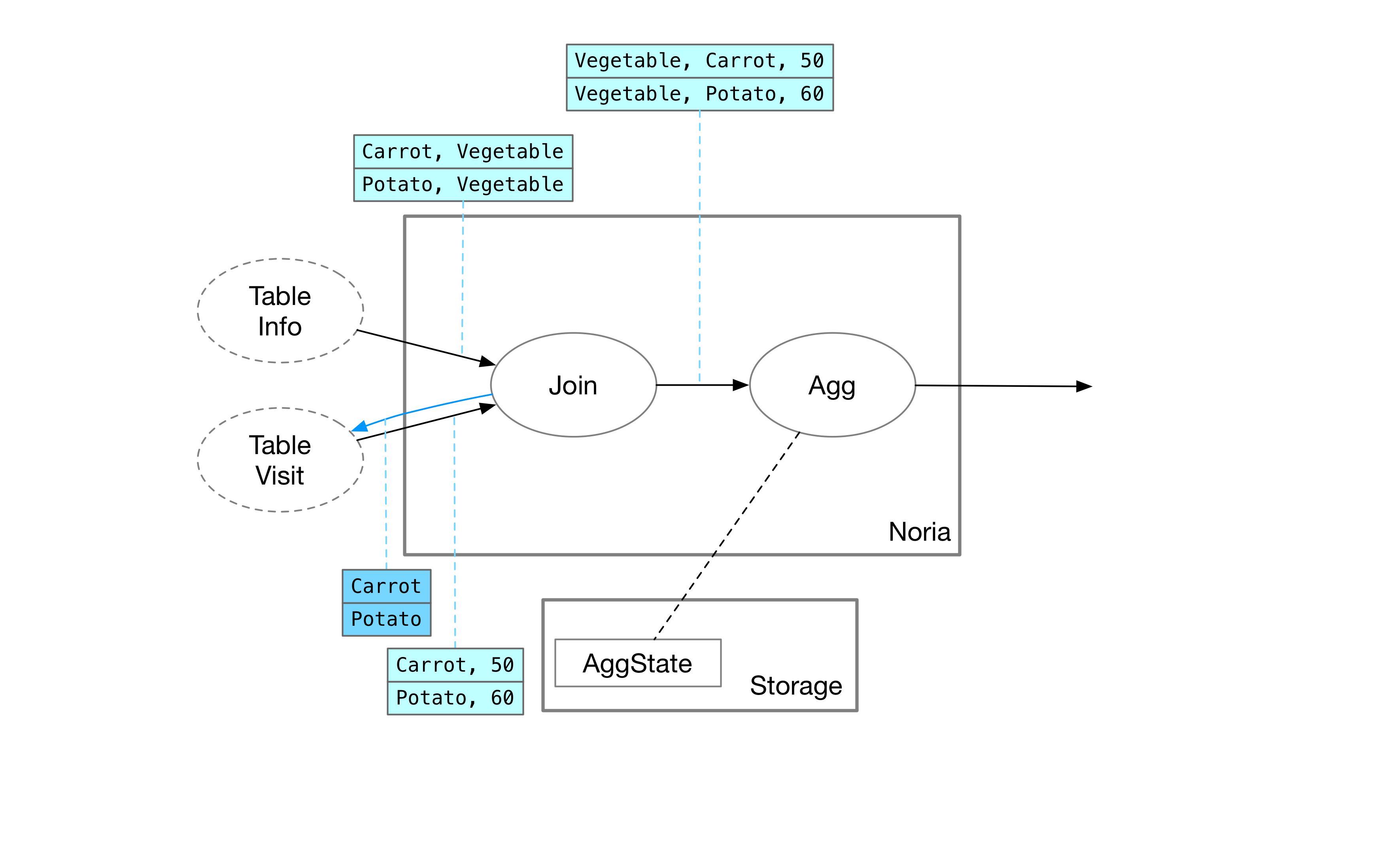
After the Visit table returns the corresponding records, the join operator can compute the Join result based on the outputs of both upqueries.
In Noria, the join operator does not need to store any actual state; it only needs to record the ongoing upquery.
Aggregation Operator Implementation
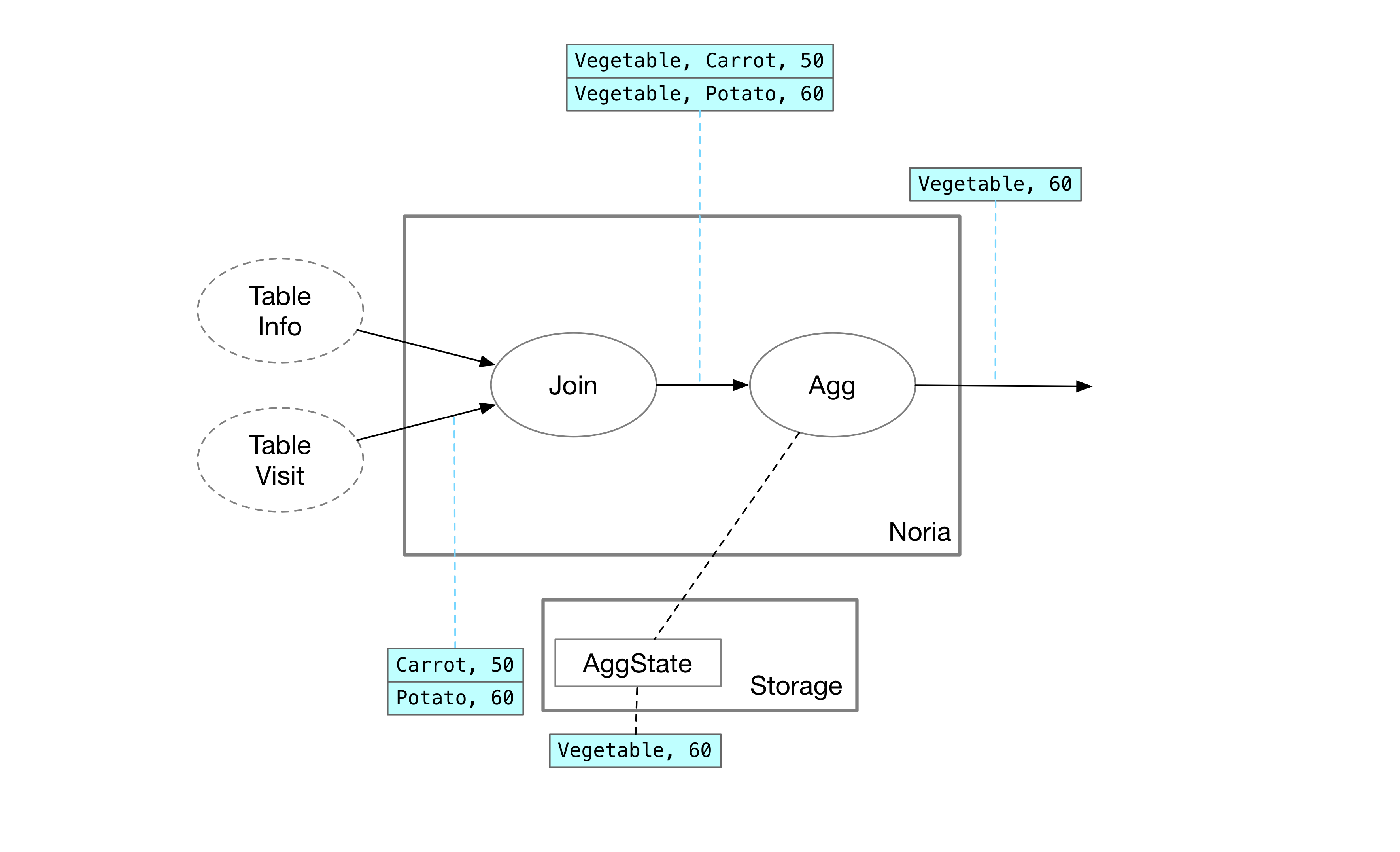
When the data arrives at the aggregation operator, Noria directly calculates the maximum value and stores it in the operator’s state. In the system described earlier, the aggregation operator’s state needs to store the complete data (all browsing records for fruits and vegetables). Noria only needs to cache the requested state, so in this query, it only records the records for vegetables. At the same time, if a deletion operation occurs upstream, Noria can directly delete the corresponding rows for vegetables to recalculate the maximum value later. Therefore, in a partial state storage system, there is no need to backtrack and find the second largest value by recording all values - simply clearing the cache is sufficient.
Summary
Streaming systems that store partial state respond to user queries in real-time using upqueries. In the implementation described in this blog post, the minimum number of states that need to be stored is required. They generally have the following characteristics:
- The data flow in the computation graph is bidirectional - data can flow from upstream to downstream and downstream to upstream through upqueries.
- Due to the need for recursive upqueries, the computation latency may be slightly larger compared to other state storage methods.
- Data consistency is difficult to achieve. The other storage methods described in this blog post can easily achieve eventual consistency, but for systems that store partial state, special care needs to be taken to handle the propagation of updates and upquery results simultaneously on the stream. The correctness of the implementation needs to be carefully proven for each operator.
- DDL/Recovery is very fast. Since the information inside operators is calculated on-demand, if a user performs operations such as adding or deleting columns on a View or performs migration, the cache can be cleared and new nodes can be allocated without the expensive cost of state recovery.
Finally, let’s compare the characteristics of streaming state stores for different state storage methods:
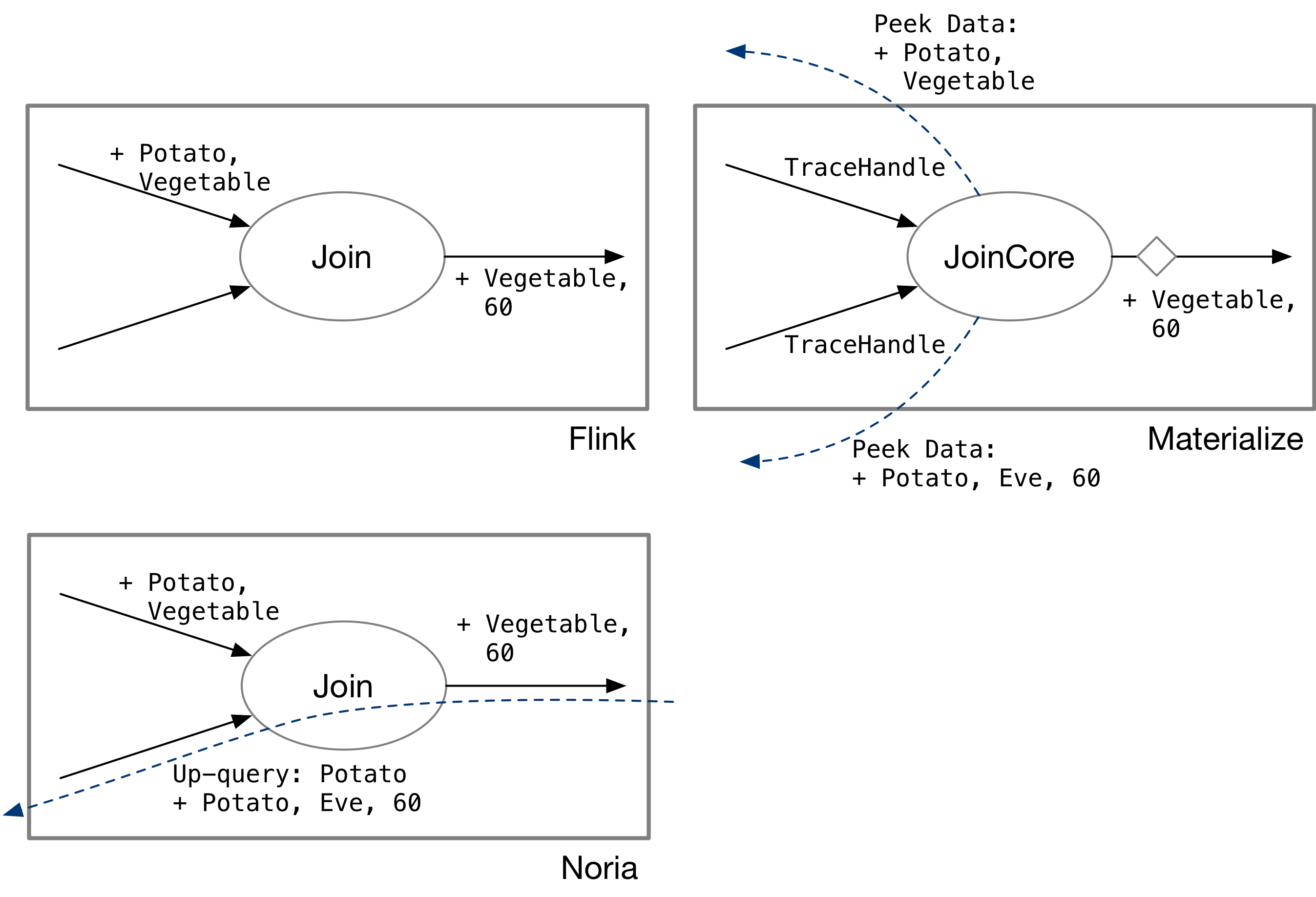
- Full state storage (e.g., Flink): Data flows on the stream.
- Shared state storage (e.g., Materialize / Differential Dataflow): Data and snapshots flow on the stream.
- Partial state storage (e.g., Noria): Data flows on the stream, and messages flow bidirectionally on the stream.
Reference
- Apache Flink
- Flink SQL
- Materialize
- Joins in Materialize
- Maintaining Joins using Few Resources
- differential-dataflow
- Noria
This blog post is translated by ChatGPT from my previous blog post, originally posted on 01/15/2022.
Feel free to comment and share your thoughts on the corresponding GitHub Discussion for this blog post.